
Pythonでデータフレームの列をインデックスにする方法です。
使用するのは、Pythonのpandasライブラリのset_indexメソッドです。
import pandas as pd
df = pd.read_csv('./sample.csv')
df.head() 実行結果: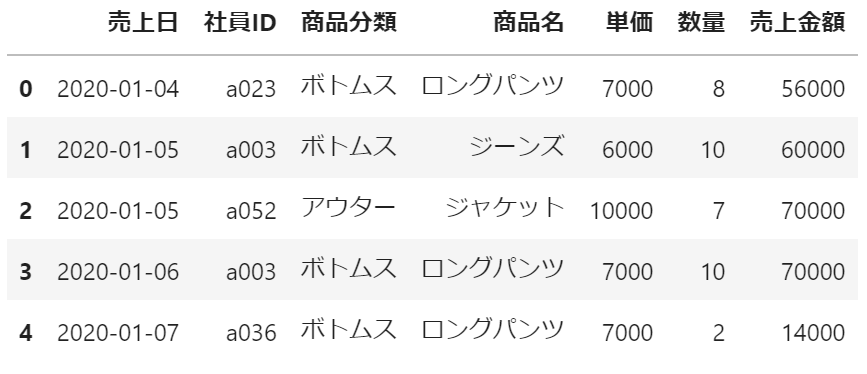
まず、set_indexメソッドの引数に、インデックスにしたい列のカラムを指定します。
なお、今回はデータの量が多いため、headメソッドで先頭の5件のみ表示させてみます。
実行します。
商品名をインデックスとして表示することができました。
df.set_index('商品名').head()実行結果: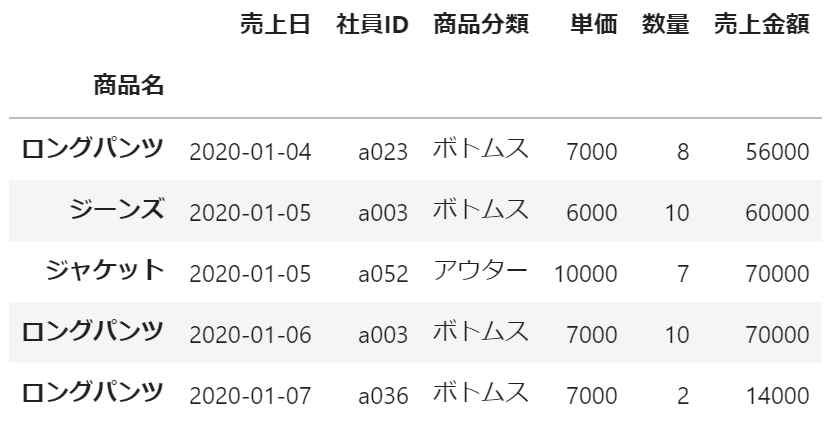
インデックスに指定した列を残しておくには、引数dropにFalseを指定します。
実行します。
指定した通りに表示することができました。
df.set_index(['商品名'], drop=False).head()実行結果: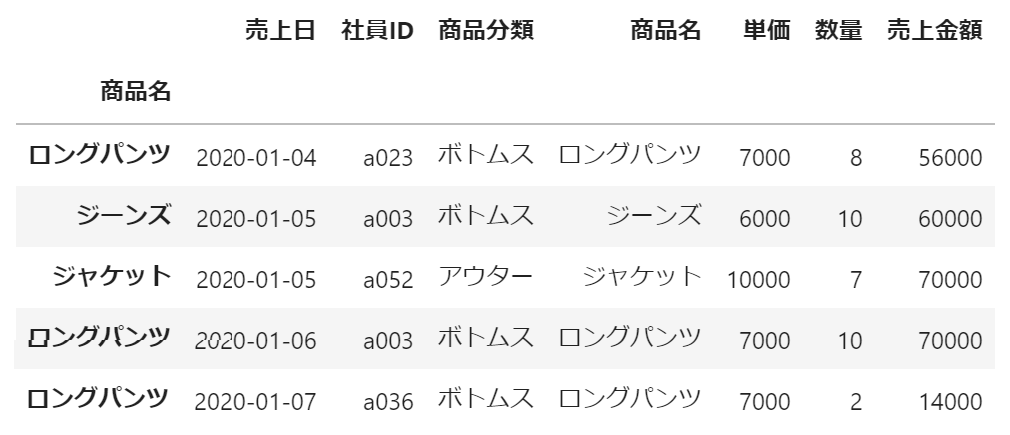
元のインデックスを残すには、引数appendにTrueを指定します。
実行します。
指定した通りに表示することができました。
df.set_index(['商品名'], append=True).head()実行結果: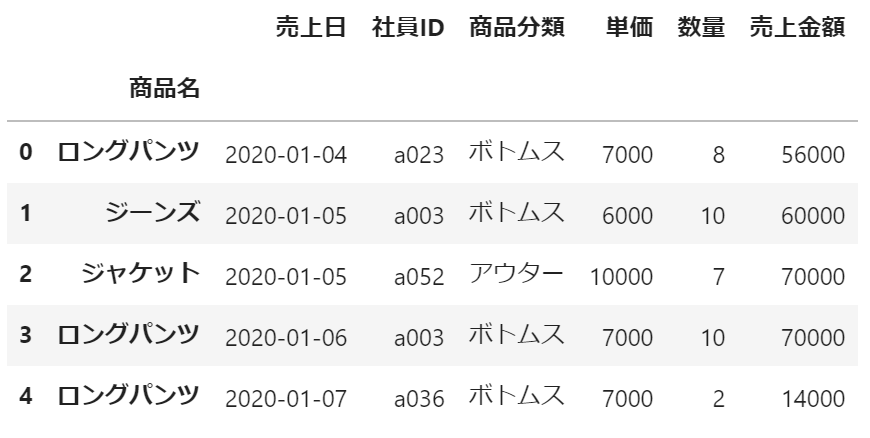
インデックスにする列を、複数指定することもできます。
引数にリストで複数のカラムを指定して実行します。
売上日と商品名をマルチインデックスとして表示することができました。
df.set_index(['売上日', '商品名']).head()実行結果: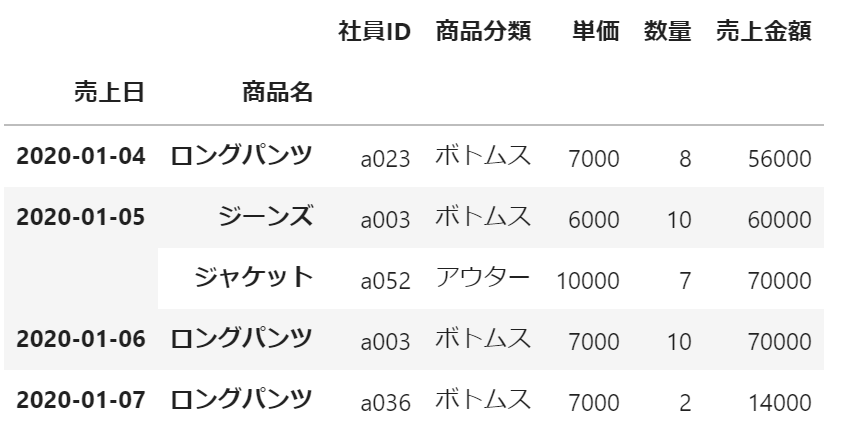
なお、set_indexメソッドに似たメソッドで、reset_indexメソッドがあります。
reset_indexメソッドでは、データフレームに新しいインデックスを附番することができます。
df.reset_index().head()実行結果:
関連メソッド
【毎日Python】Pythonでデータフレームに新しいインデックスを附番する方法|DataFrame.reset_index

