
エクセルで学ぶ人工知能編
この記事の執筆・監修

テクノロジーアンドデザインカンパニー株式会社のCEO。
日本最大級のプログラミング教育のYouTubeチャンネル「キノコード」や、プログラミング学習サービス「キノクエスト」を運営。
著書「あなたの仕事が一瞬で片付くPythonによる自動化仕事術」や、雑誌「日経ソフトウエア」や「シェルスクリプトマガジン」への寄稿など実績多数。
カリフォルニアの住宅価格データセットの説明
# 今回はGoogleコラボを使うので不要
!pip install scikit-learn
!pip install pandasまず、今回のエクセルを使った重回帰分析で使用するデータセ ットについて説明します。
使用するデータは、アメリカの都市カリフォルニアの住宅価格に関するデータセットです。
このデータセットは、scikit-learn(サイキットラーン)ライブラリの中に入っています。
データセットの準備
はじめに、scikit-learn(サイキットラーン)ライブラリからデータを取得し、Excelファイルを作成します。
今回は、Google Colaboratoryを使用します。
pythonの実行環境が整っていない方でも、Googleアカウントさえあればすぐに使うことができます。
詳しい使い方を知りたい方は、こちらの動画をご参照ください。
では、GoogleChoromeを開き、こちらのURL(https://colab.research.google.com/ )にアクセスします。
すると、このようなページが開きます。
「ノートブックを新規作成」をクリックします。
ノートブックが開きました。
import pandas as pd
from sklearn.datasets import fetch_california_housingデータセットを読み込む準備をしていきましょう。
カリフォルニアの住宅価格のデータセットの抽出に使用するライブラリをインポートします。
このように書きましょう。
まず、pandasをインポートします。
そして、scikit-learnのデータセットの中の、カリフォルニアの住宅価格のデータセットをインポートします。
実行します。
インポートができました。
ca_data=fetch_california_housing(as_frame=True)
ca_data次に、カリフォルニアの住宅価格のデータセットを読み込みます。
fetch_california_housing()という関数を変数ca_dataに代入します。
データを取得するために、引数as_frameにはTrueを渡します。
そして、ca_dataの中身を確認してみましょう。
実行します。
たくさんの情報が表示されました。
このデータは辞書型になっていることがわかります。
dataの中には説明変数の値が入っており、targetの中には目的変数の値が入っています。
今回はこのMedHouseVal、すなわち、ある地区の住宅価格の中央値が目的変数です。
そして、frameには説明変数の略称が入っています。
その地区の収入の中央値、築年数、平均の部屋数などが入っていることがわかります。
df_X = pd.DataFrame(ca_data.data)
df_y = pd.DataFrame(ca_data.target)
df = pd.concat([df_X, df_y], axis=1)
dfそれでは、このデータセットをデータフレームの形にしましょう。
変数df_Xにca_dataのdataをデータフレーム形式で代入します。
同様に、変数df_yにca_dataのtargetをデータフレーム形式で代入します。
そして、concat関数を用いて、df_Xとdf_yを結合します。
引数axisに1を渡して、横方向に結合します。
dfの中身を確認してみましょう。
実行します。
データセットがデータフレーム形式で抽出できました。
ただし、データが2万件以上あります。
エクセルで分析するにはデータが多すぎるので最初の300件だけを抽出しましょう。
df2 = df.iloc[:300, :]
df2データフレームのilocプロパティを使うと、データの抽出ができます。
ilocと書き、角括弧の中に抽出する行と列を,(カンマ)で区切って指定します。
抽出する行の方は、:(コロン)300と書きます。
こうすると先頭から300件の行を抽出できます。
次に,(カンマ)を書きます。
抽出する列の方は、:(コロン)だけを書きます。
こうすると全ての列を抽出できます。
抽出したデータフレームを変数df2に代入し、df2の中身を確認してみましょう。
実行します。
最初の300件のデータの、全てのカラムを抽出できています。
df3 = df2[["HouseAge", "AveRooms", "MedHouseVal"]]
df3この中から今回使用するカラムだけを抽出しましょう。
df2の後ろに角括弧を2つ書き、データフレームとして抽出します。
角括弧の中に抽出したい"HouseAge","AveRooms","MedHouseVal"を書きます。
このカラムはそれぞれ築年数の中央値、平均の部屋数、住宅価格の中央値を表しています。
抽出したデータフレームを変数df3に代入し、中身を確認してみましょう。
実行します。
3つのカラムを抽出できています。
df3.to_excel("data.xlsx", index=False)このデータフレームをエクセル形式で保存しましょう。
データフレームのto_excelメソッドを使い、引数にファイル名を渡します。
今回はファイル名をdata.xlsxとして保存します。
またインデックスは必要ないので、引数indexにFalseを渡しましょう。
実行します。
左のタブを開き、フォルダを確認します。
エクセルファイルが保存できました。
右クリックでダウンロード、このエクセルファイルを使って説明を進めます。
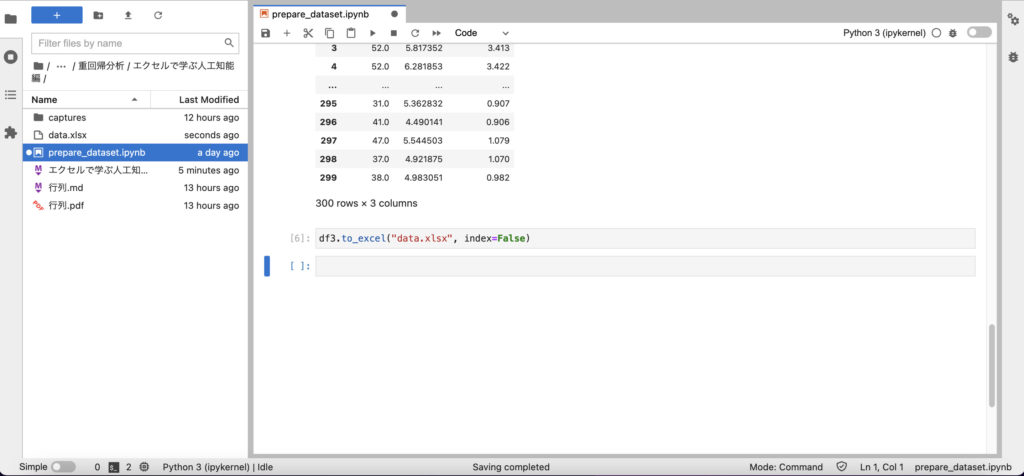
エクセルで散布図を作成(Windowsを使用)
書き出したデータをエクセルで開くとこのようになっていると思います。
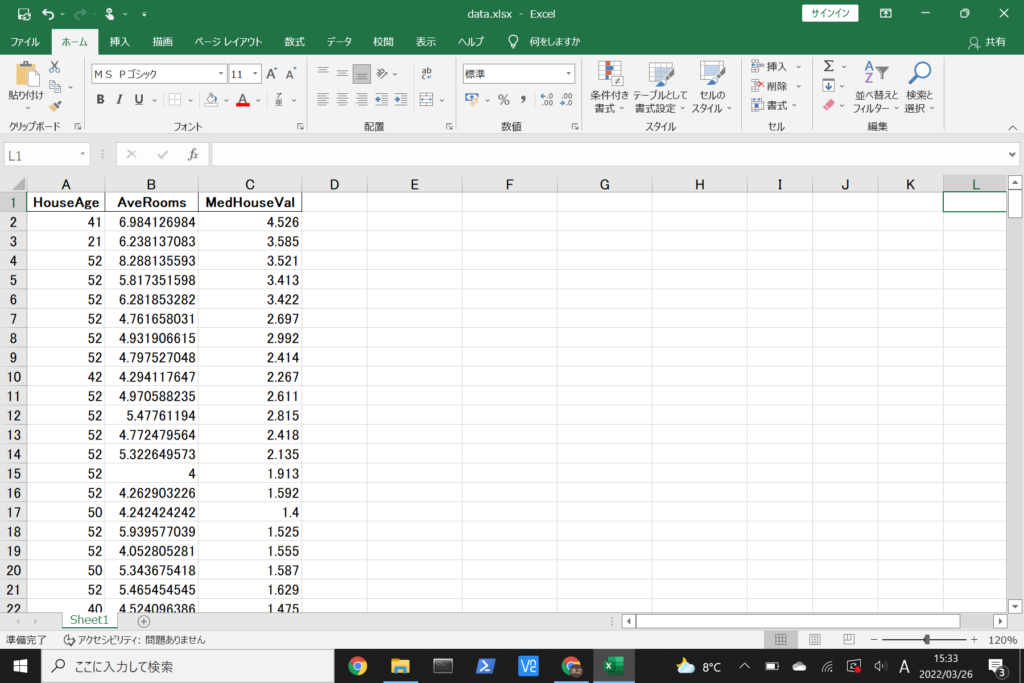
左から、築年数の中央値、平均の部屋数、住宅価格の中央値のデータです。
このデータを散布図で可視化してみましょう。
まず、築年数と住宅価格の散布図を作成します。
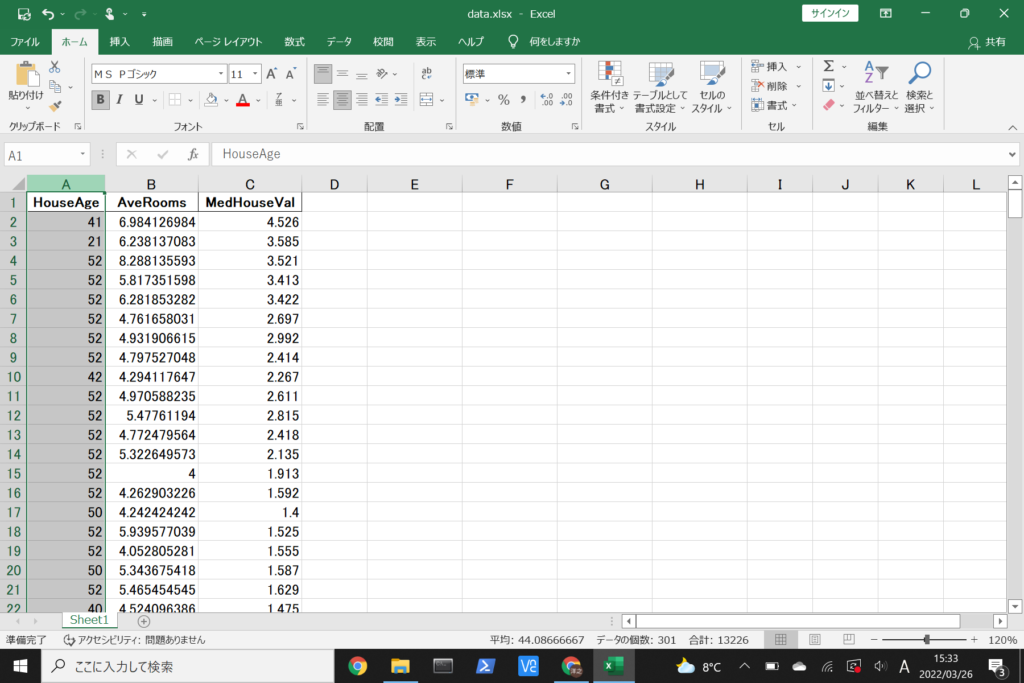
A列をクリックしてA列全体を選択します。
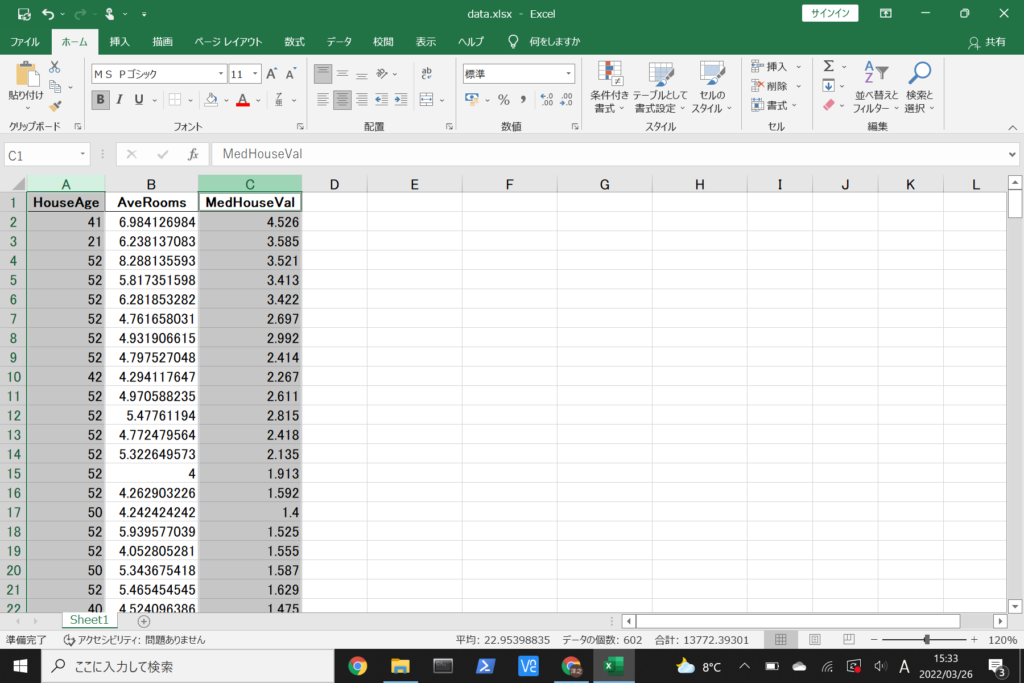
次にコントロールキーを押しながらC列をクリックしてC列全体も選択します。
挿入タブをクリックし、グラフの中から散布図を選択します。
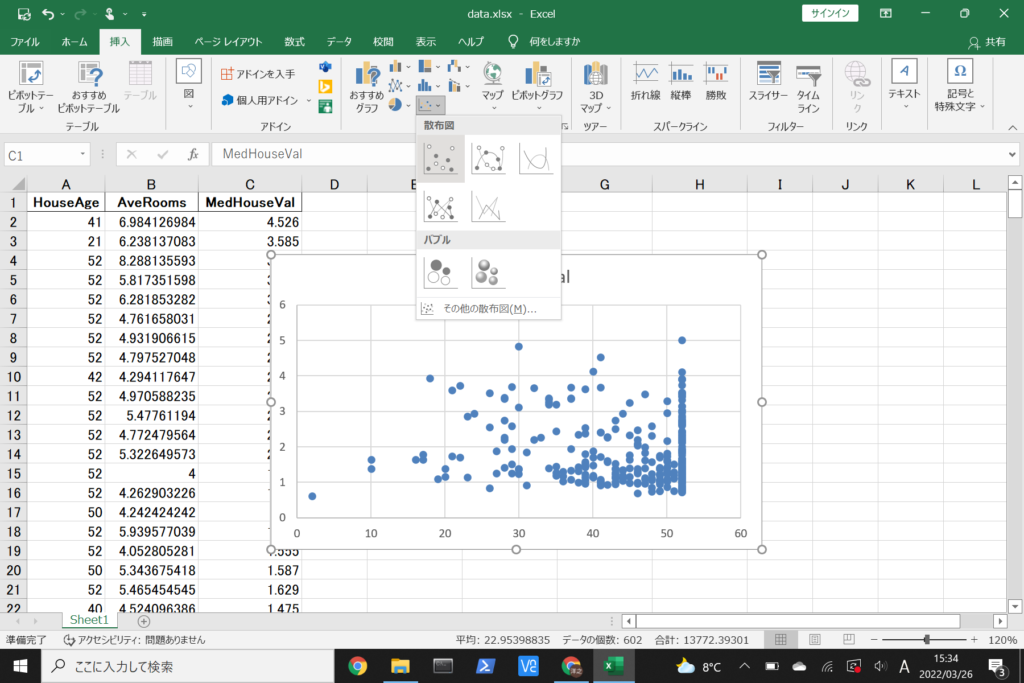
そうすると散布図を作成できます。
横軸が築年数、縦軸が住宅価格を表しています。
築年数が高いほど、住宅価格は低くなる傾向があるように見えます。
次に、部屋数と住宅価格の散布図を作成します。
今度はB列をクリックしながら、C列まで選択します。
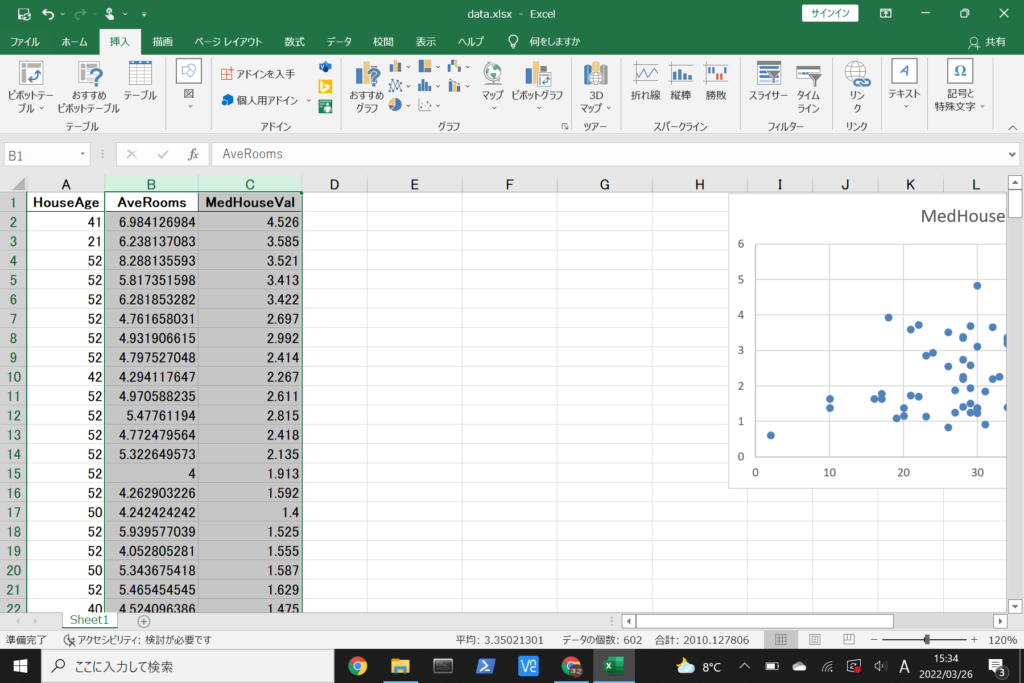
そして、同じように挿入タブから散布図を選択します。
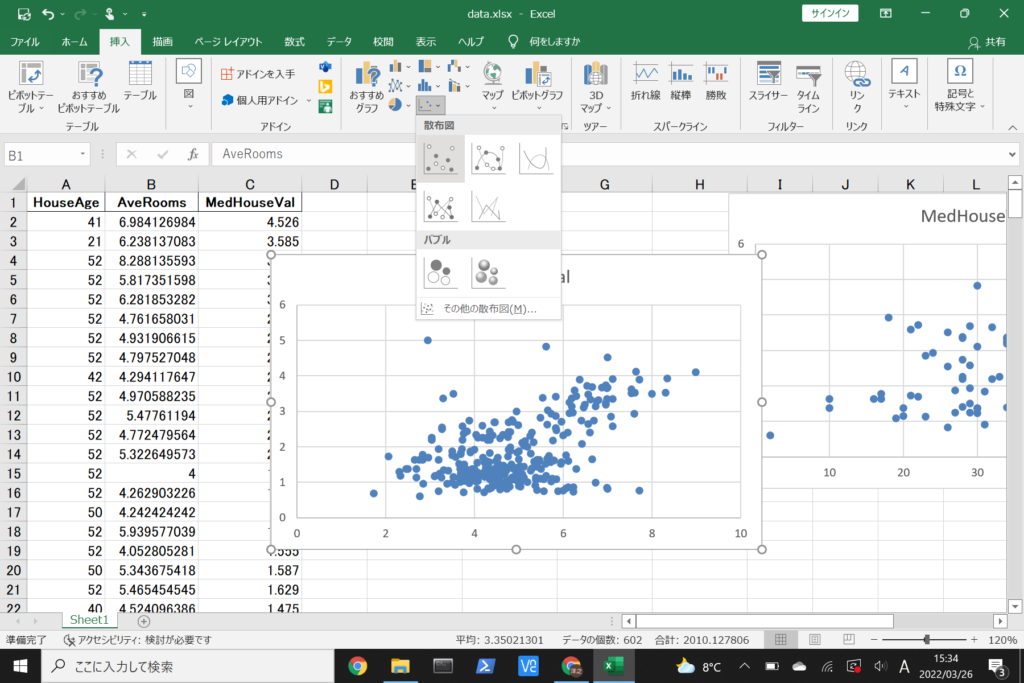
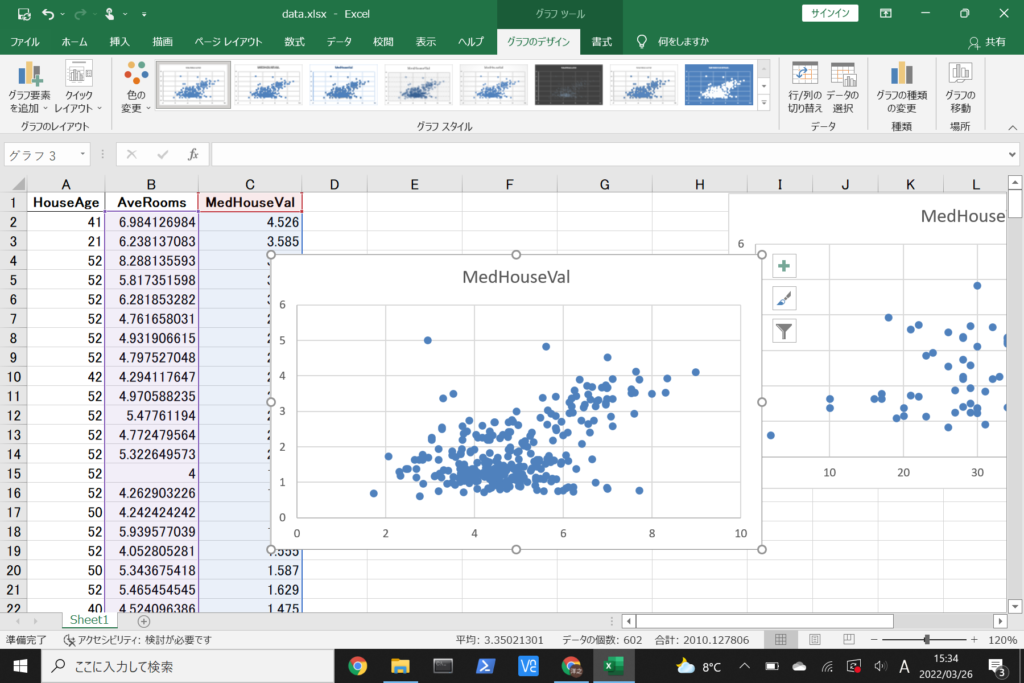
先ほどと同様に散布図を作成できました。
今度は横軸が部屋数、縦軸が住宅価格を表しています。
部屋数が多いほど、住宅価格は高くなる傾向がありそうです。
エクセルで重回帰分析(Windowsを使用)
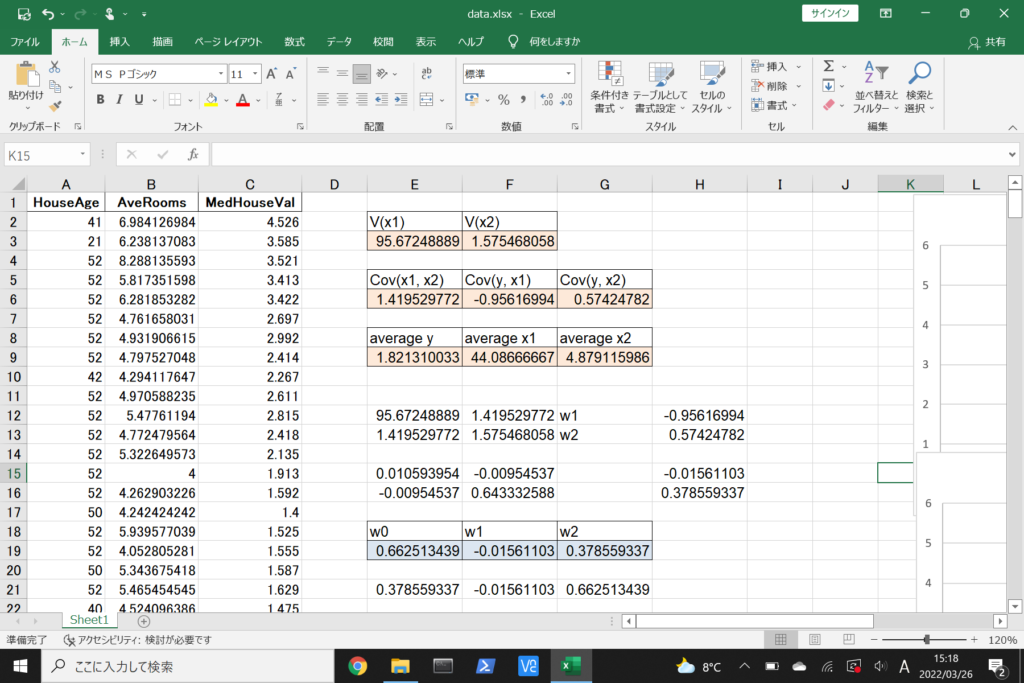
数式に沿って回帰方程式を導出
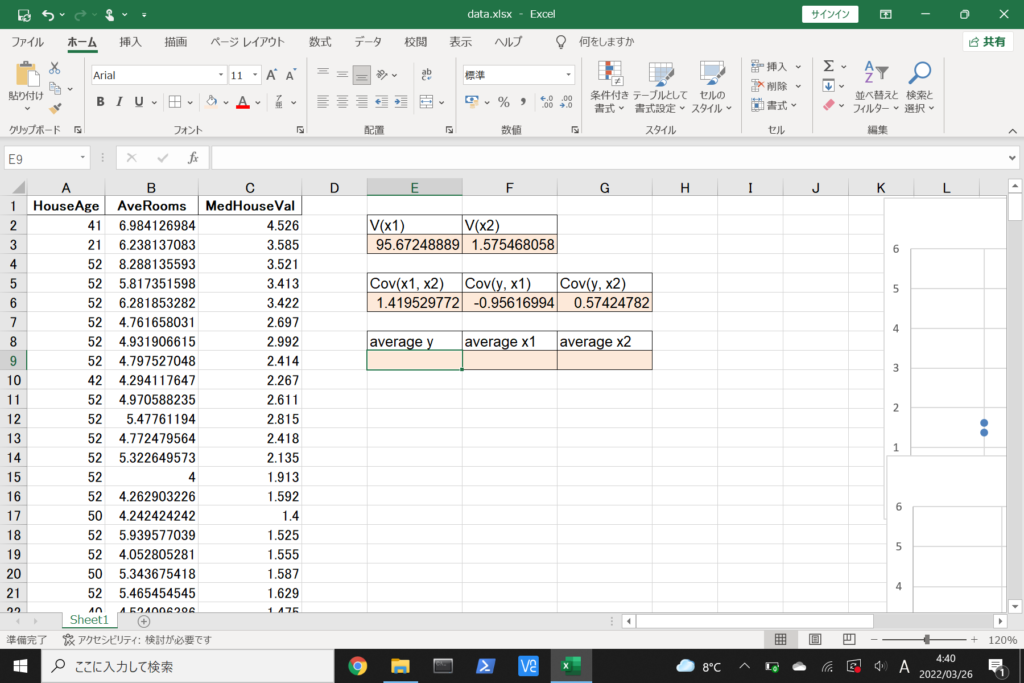
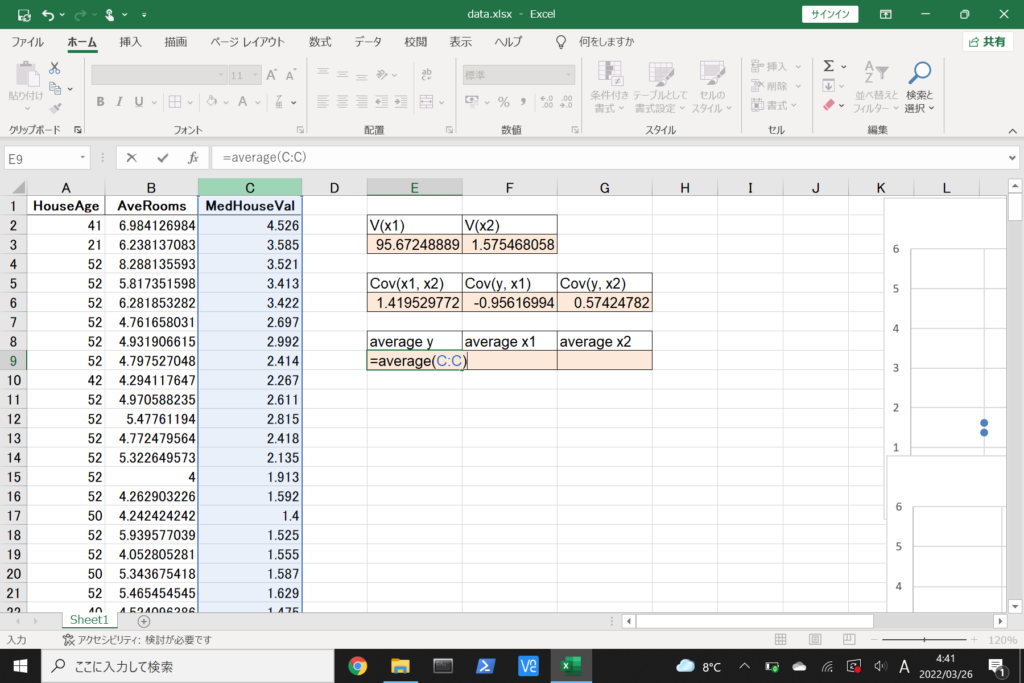
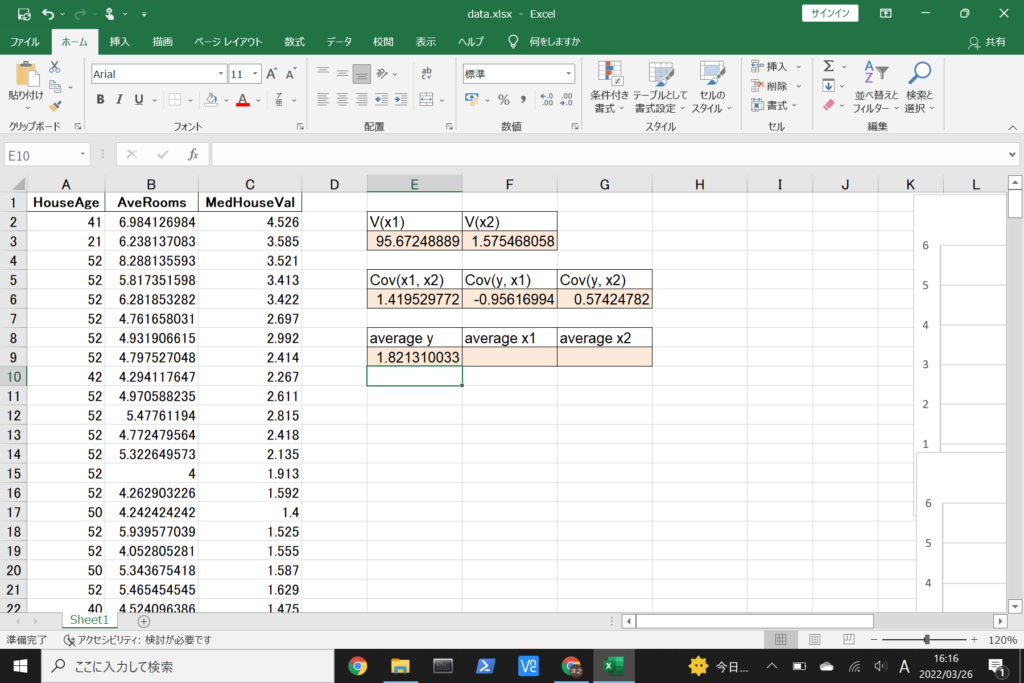
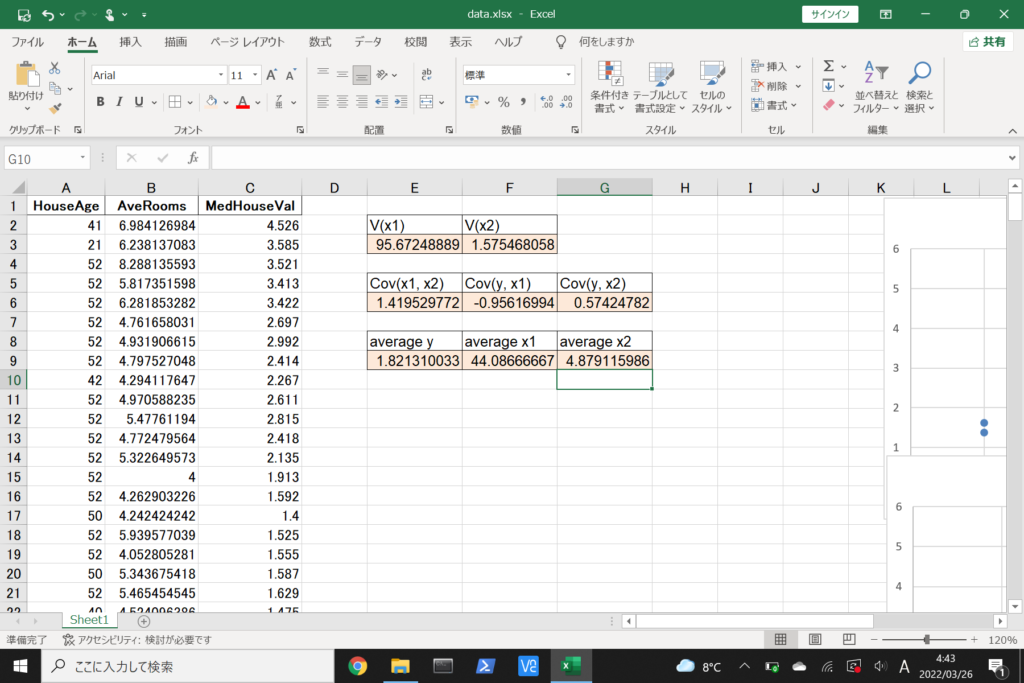
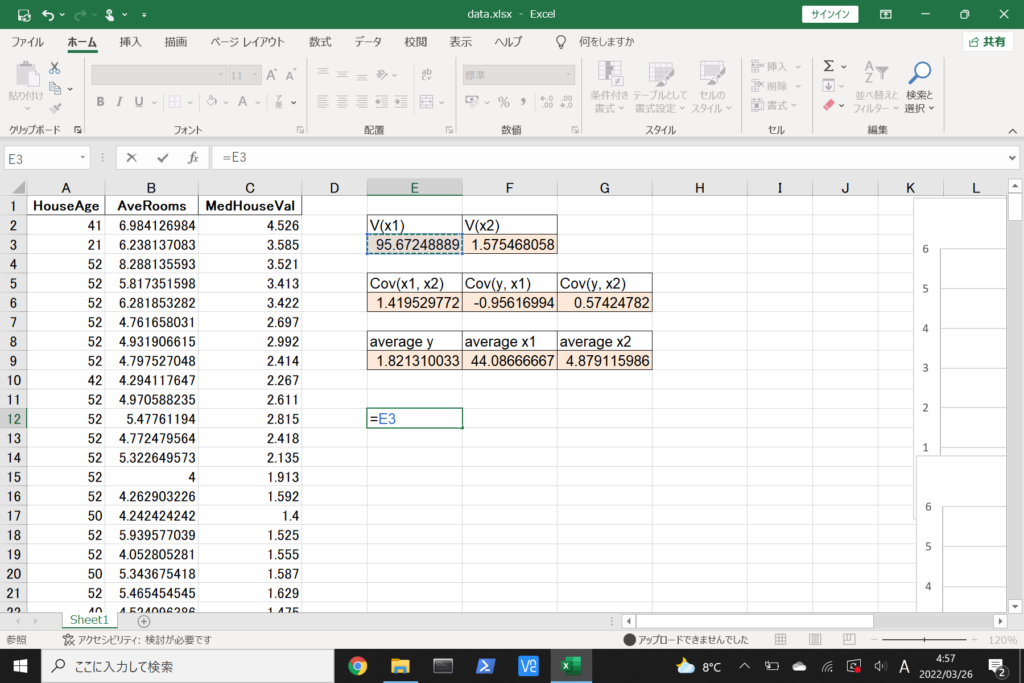
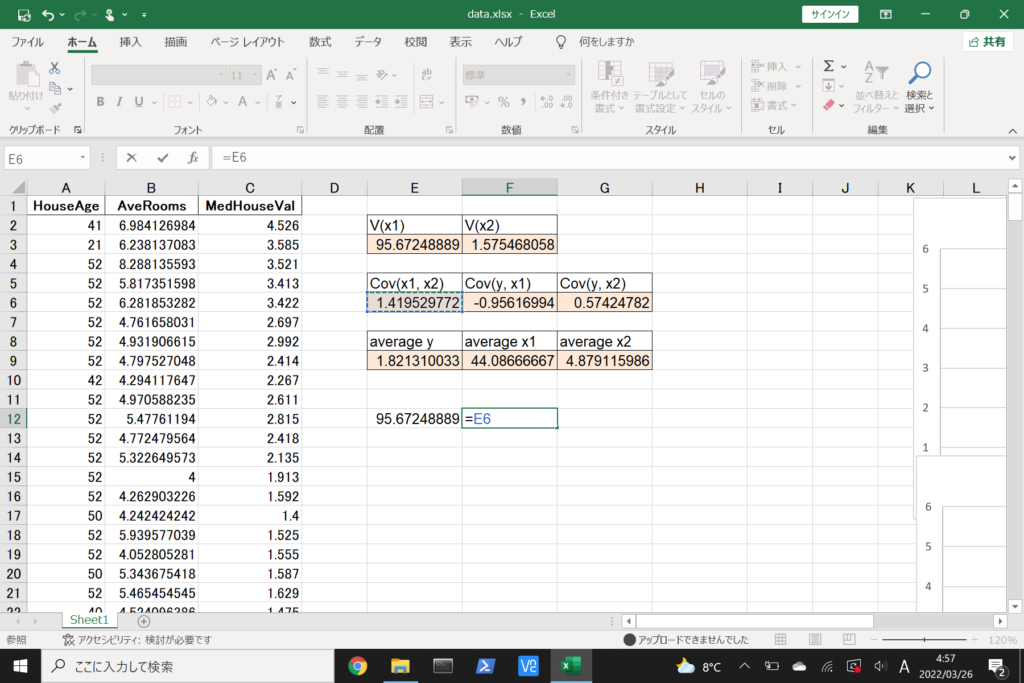
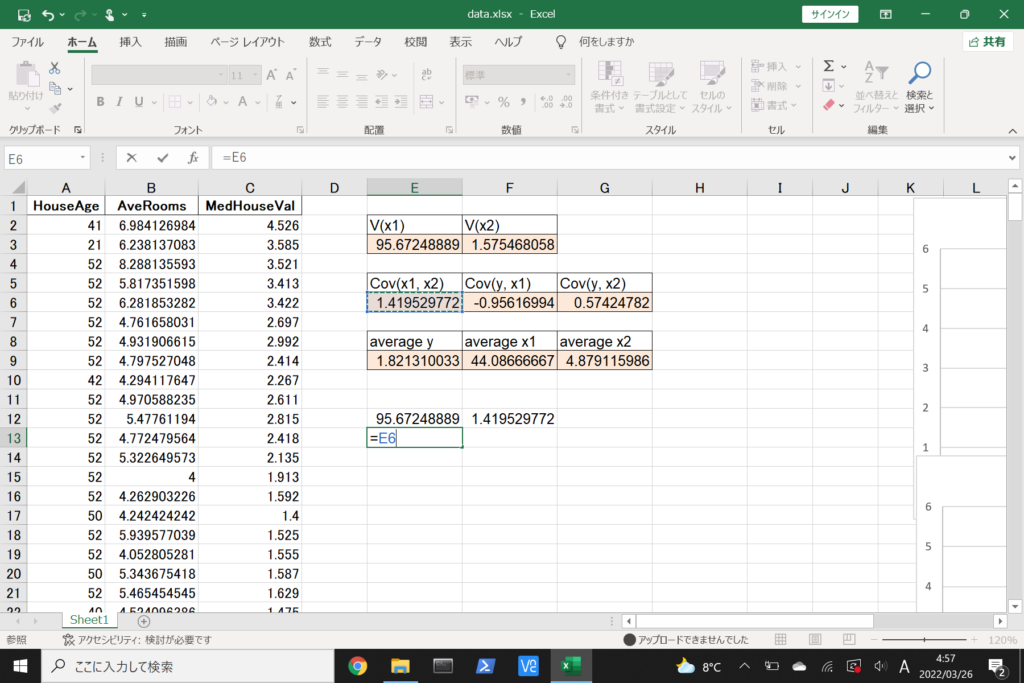
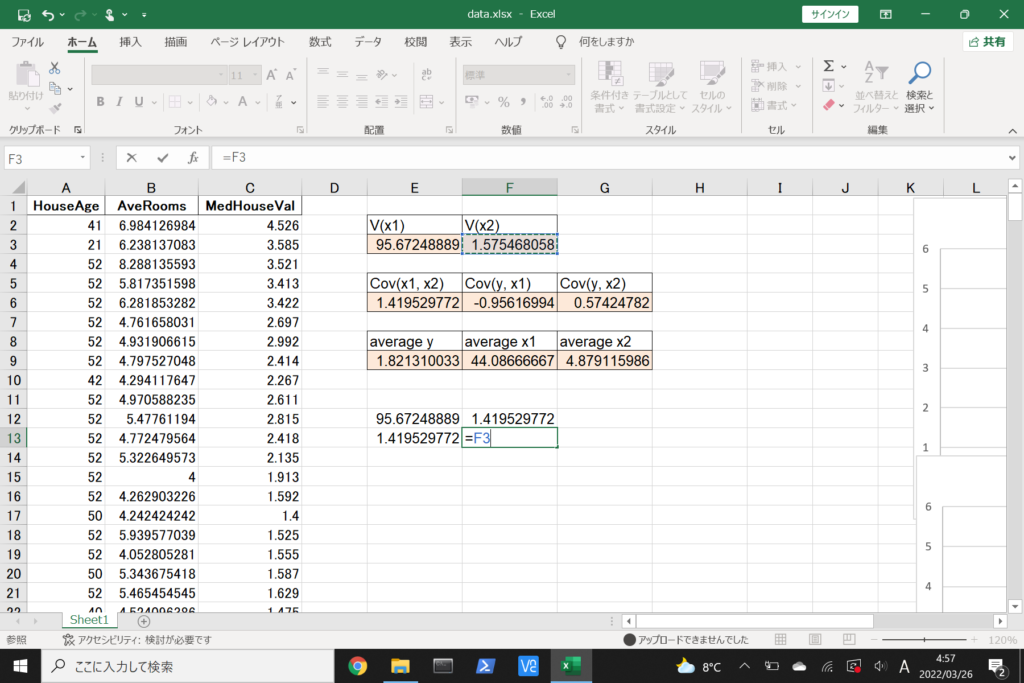
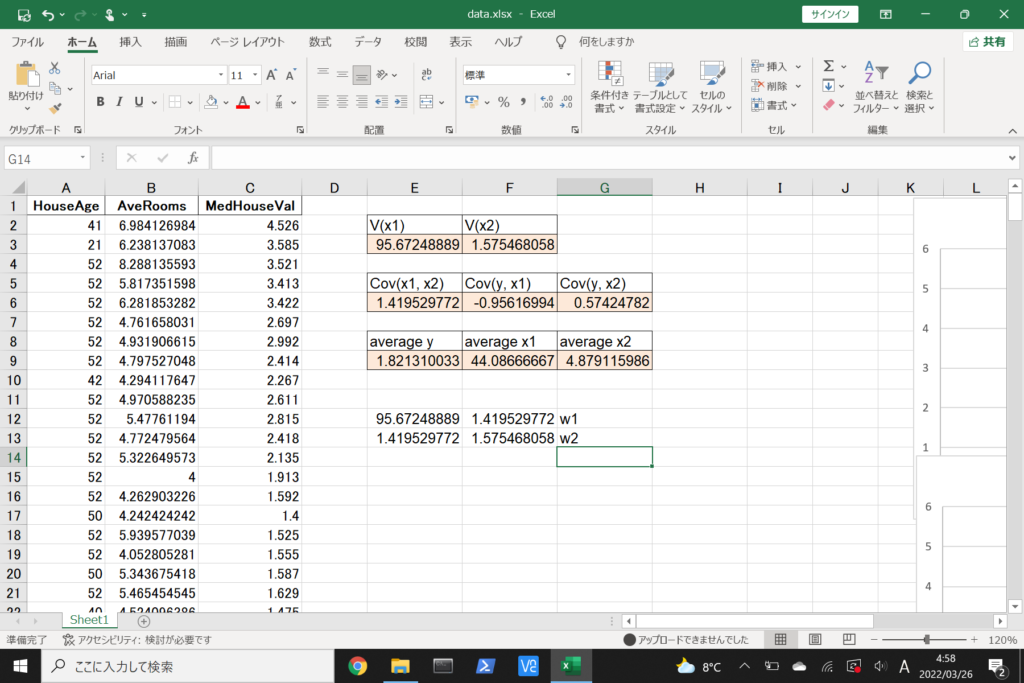
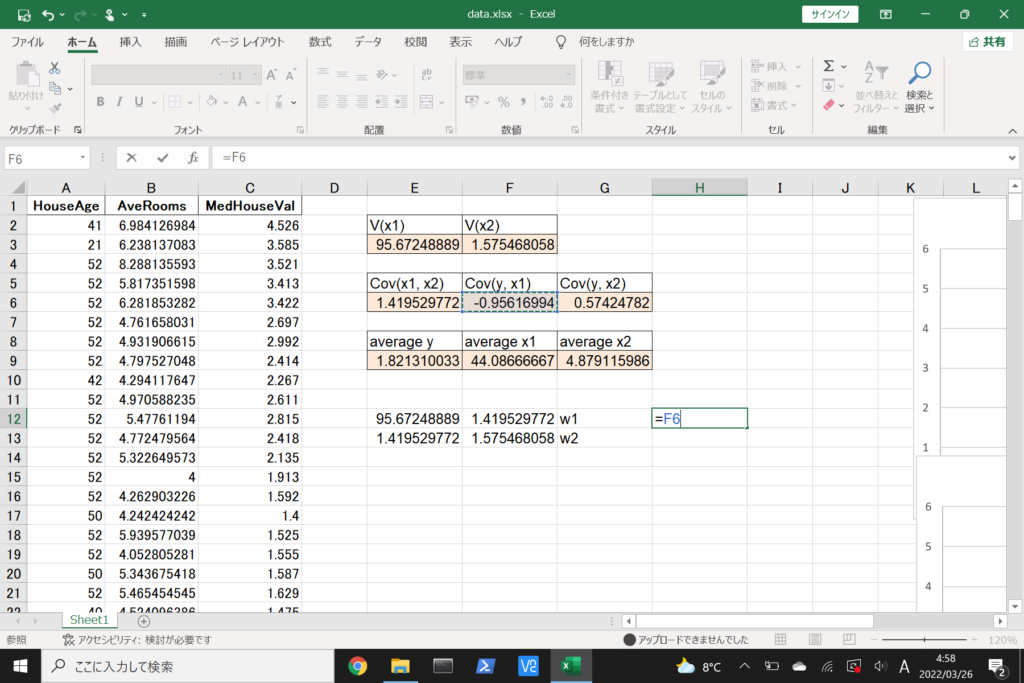
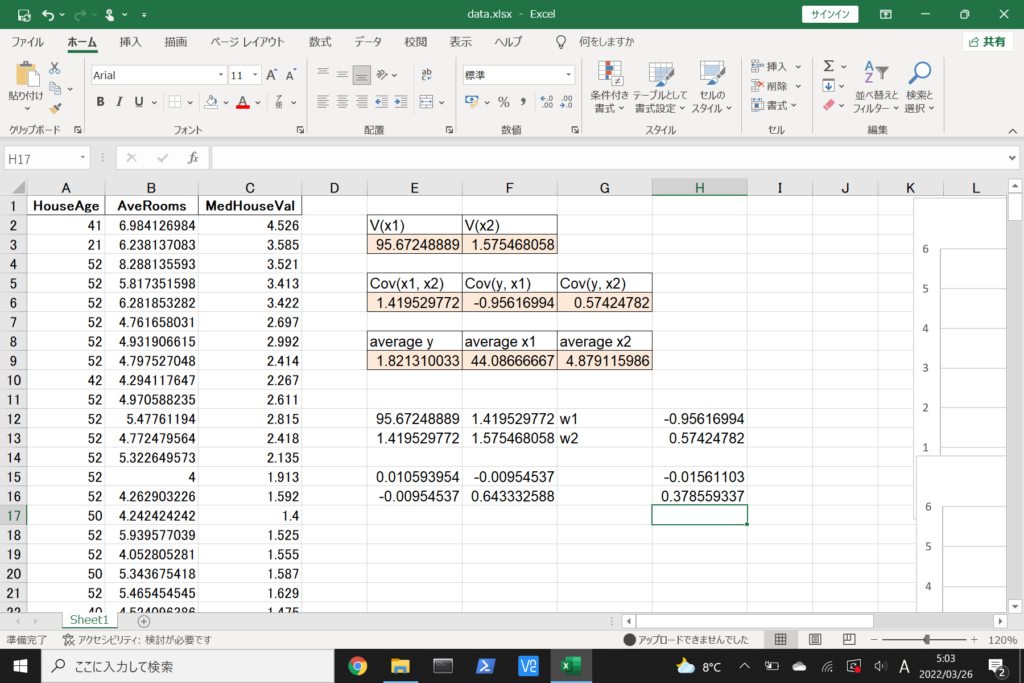
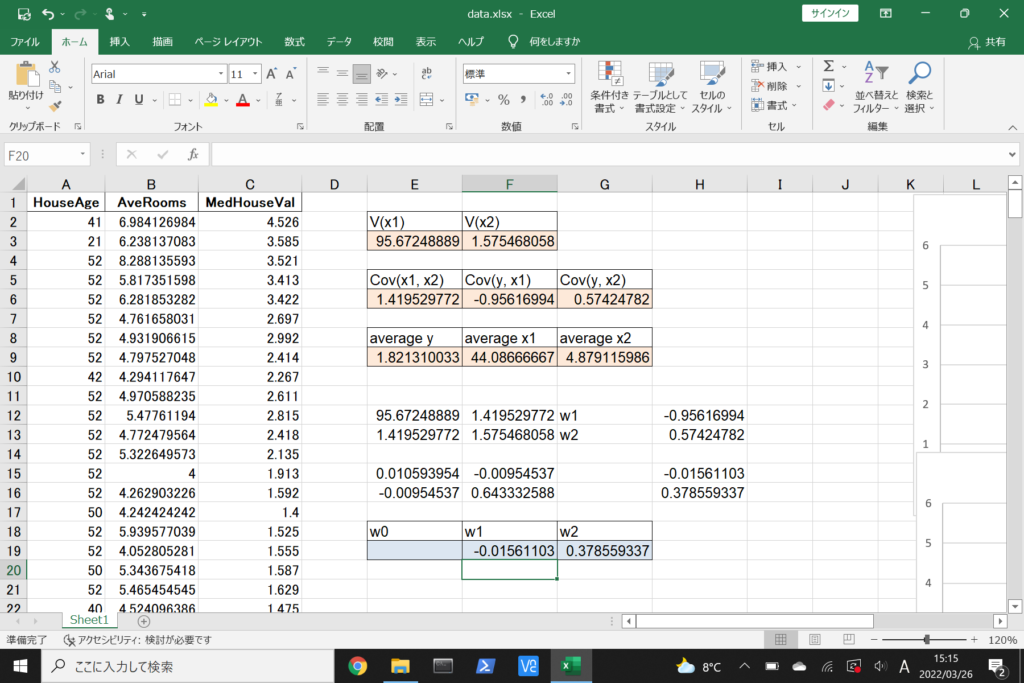
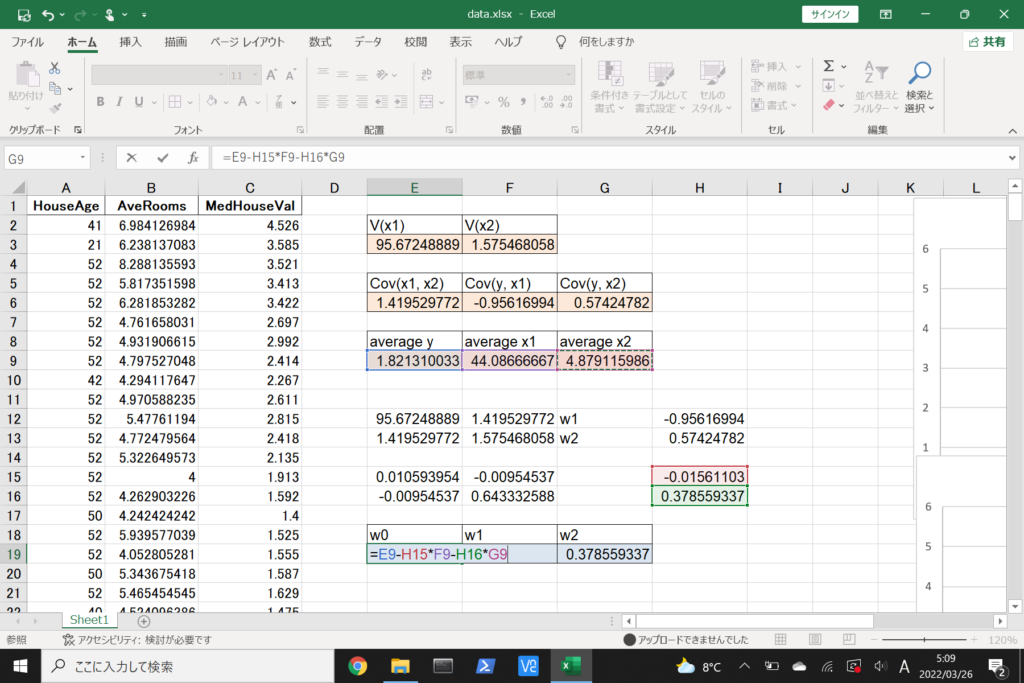
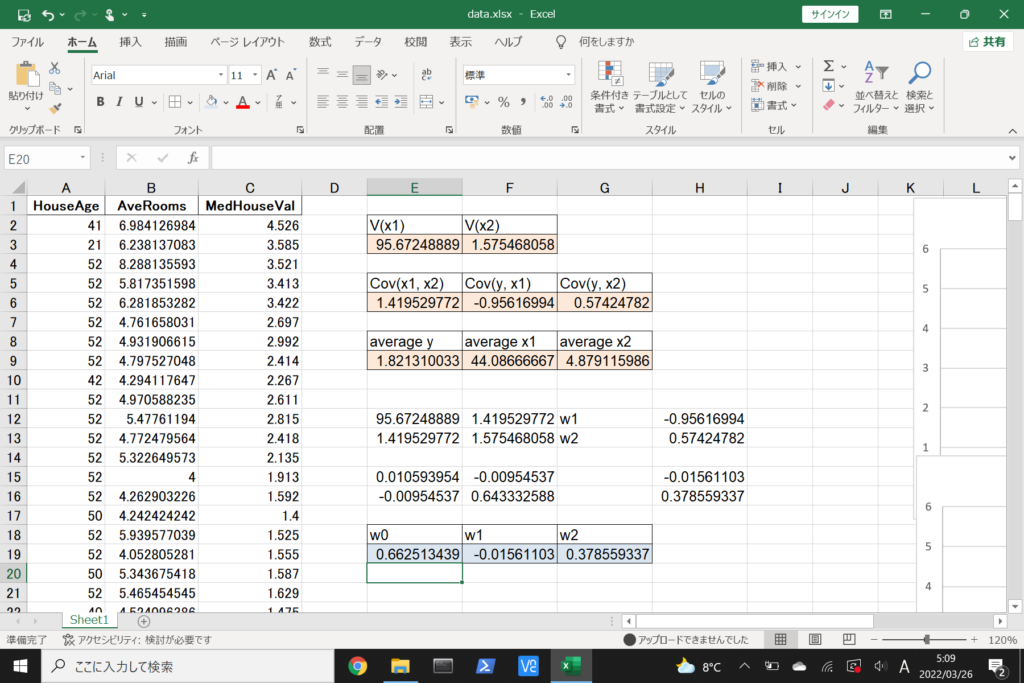
それでは、このデータを使って重回帰分析を行ってみましょう。
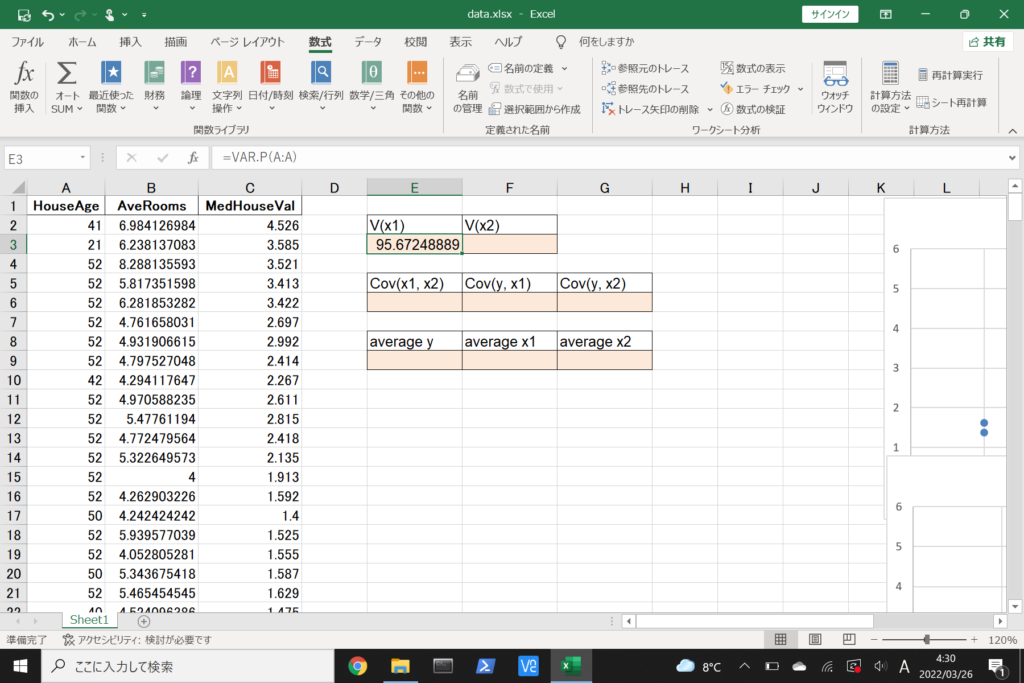
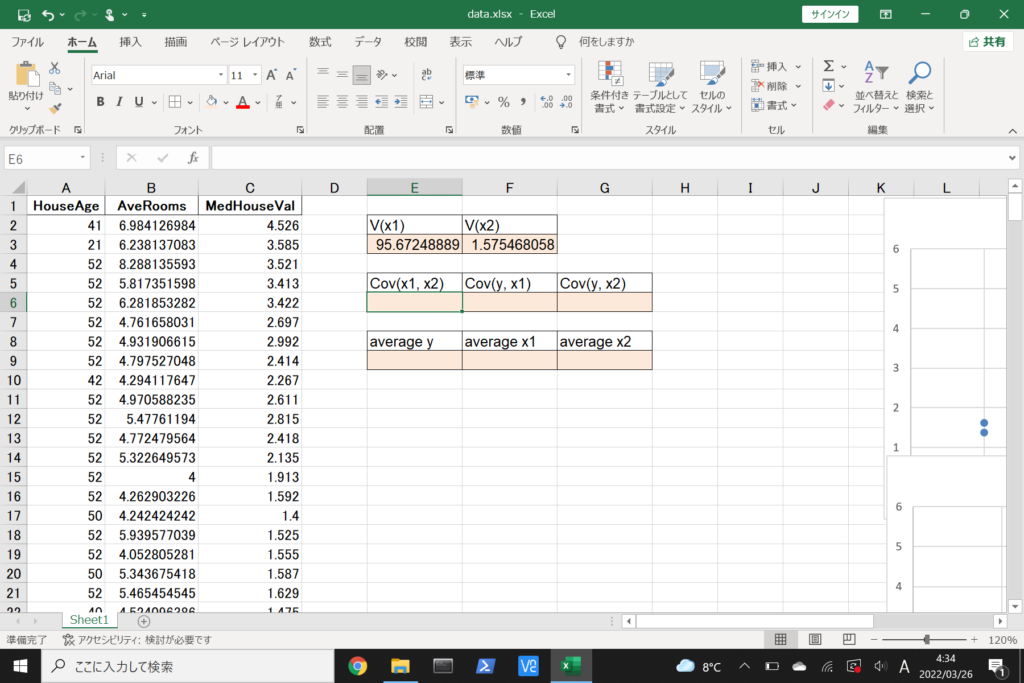
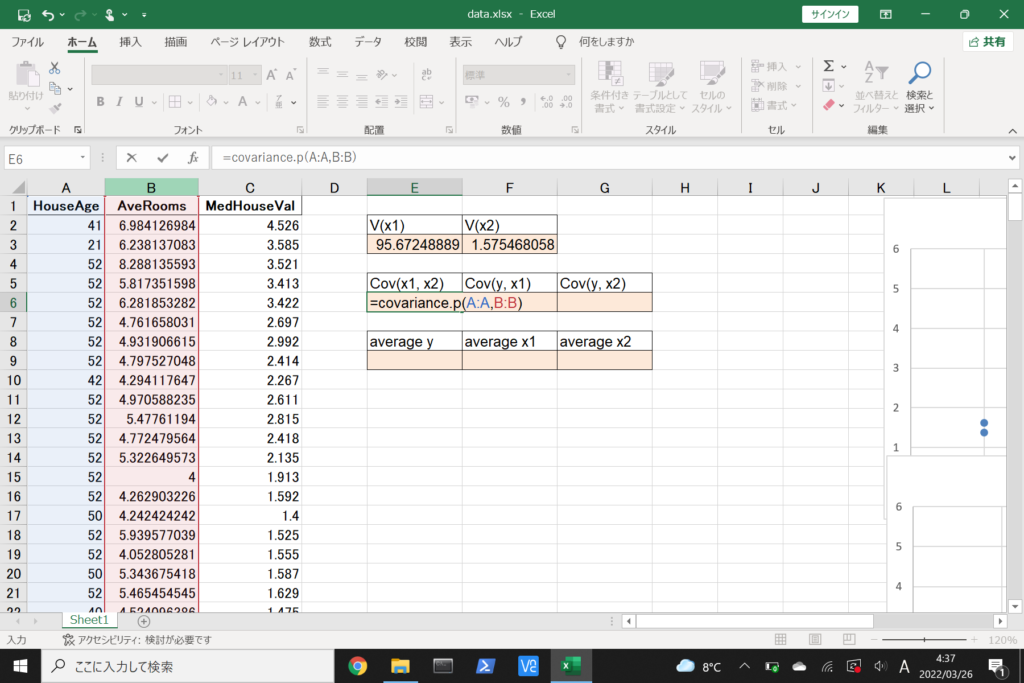
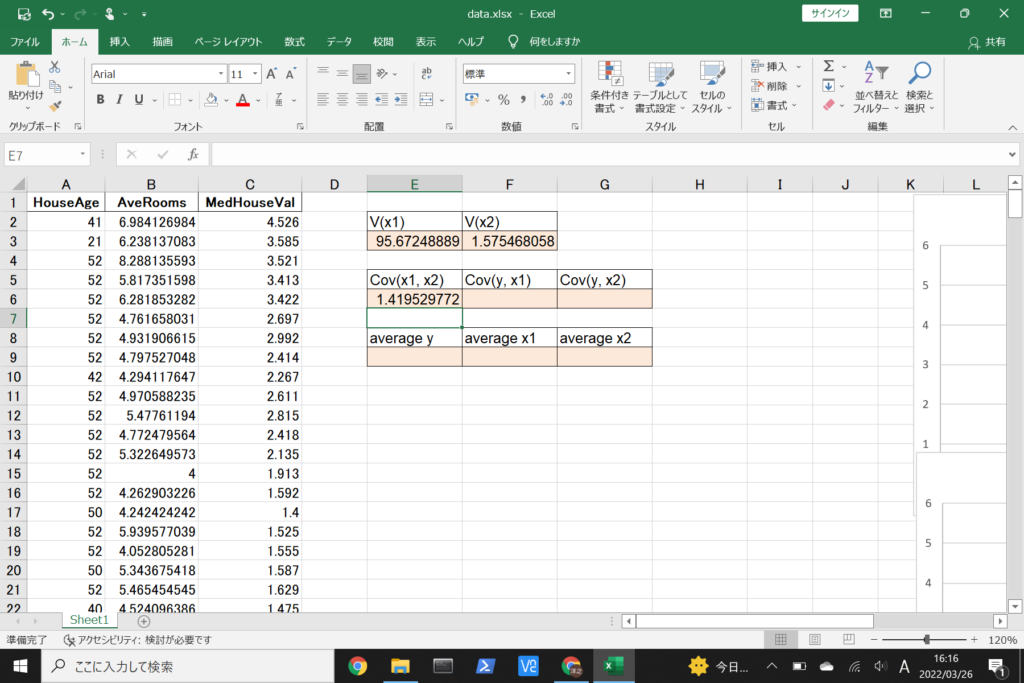
まず、数式に沿って重回帰分析を行います。
数式を使って理解編で説明したとおり、重回帰分析の回帰方程式はこのような式で表せるんでしたね。
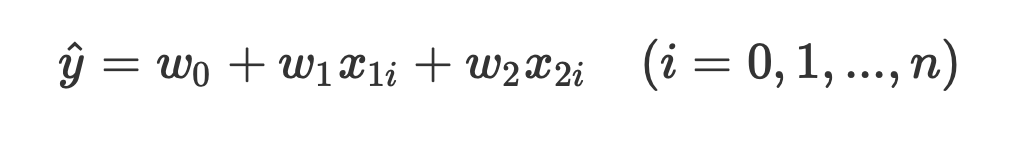

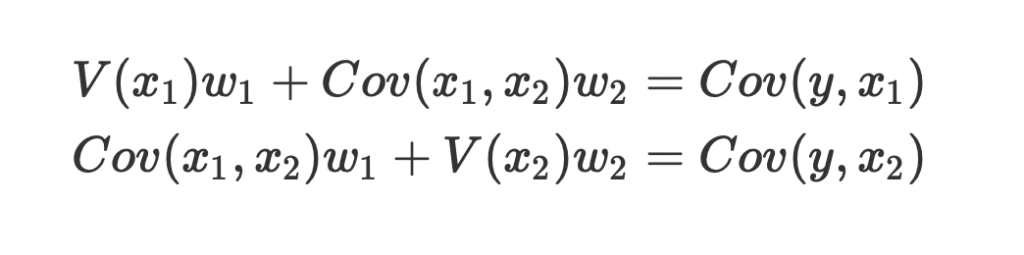

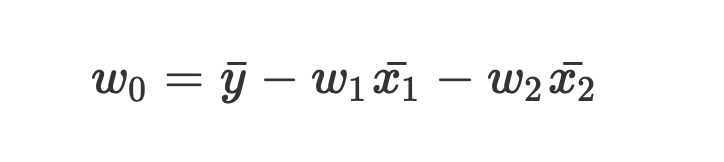

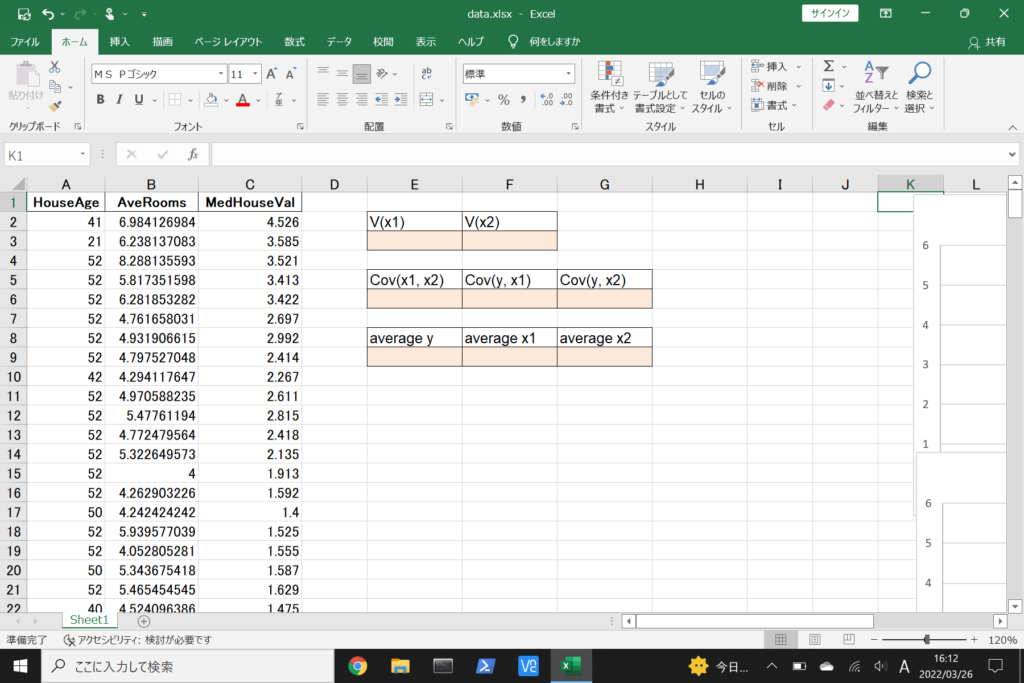

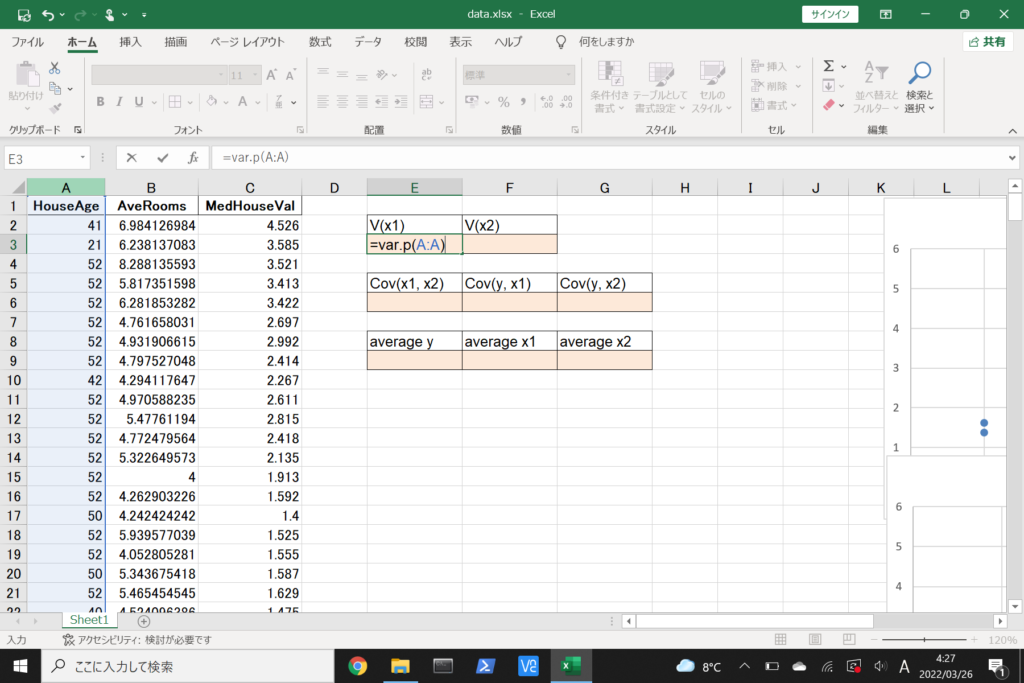









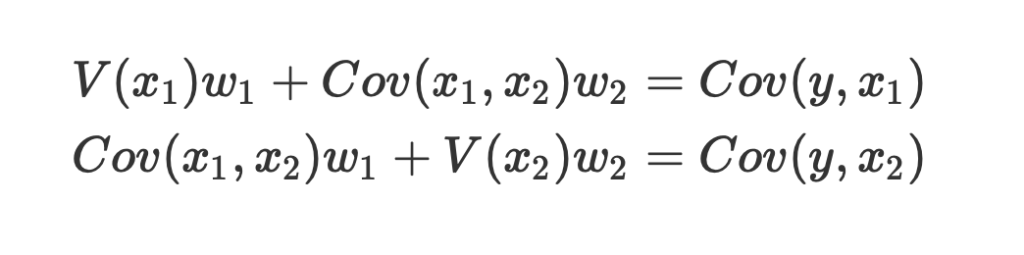


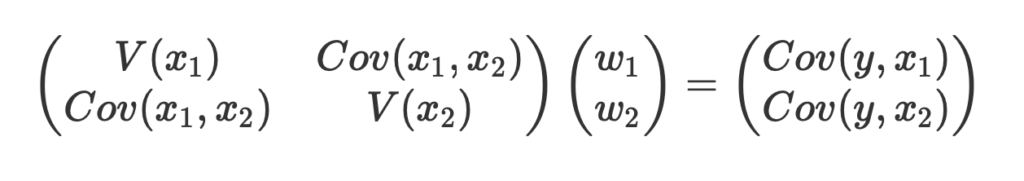

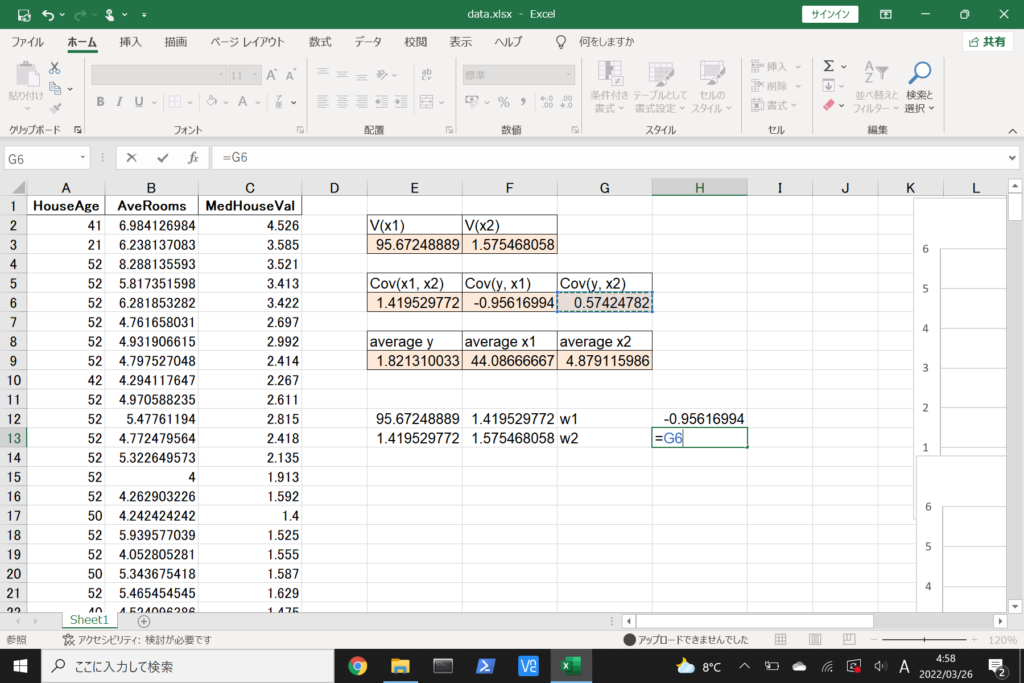

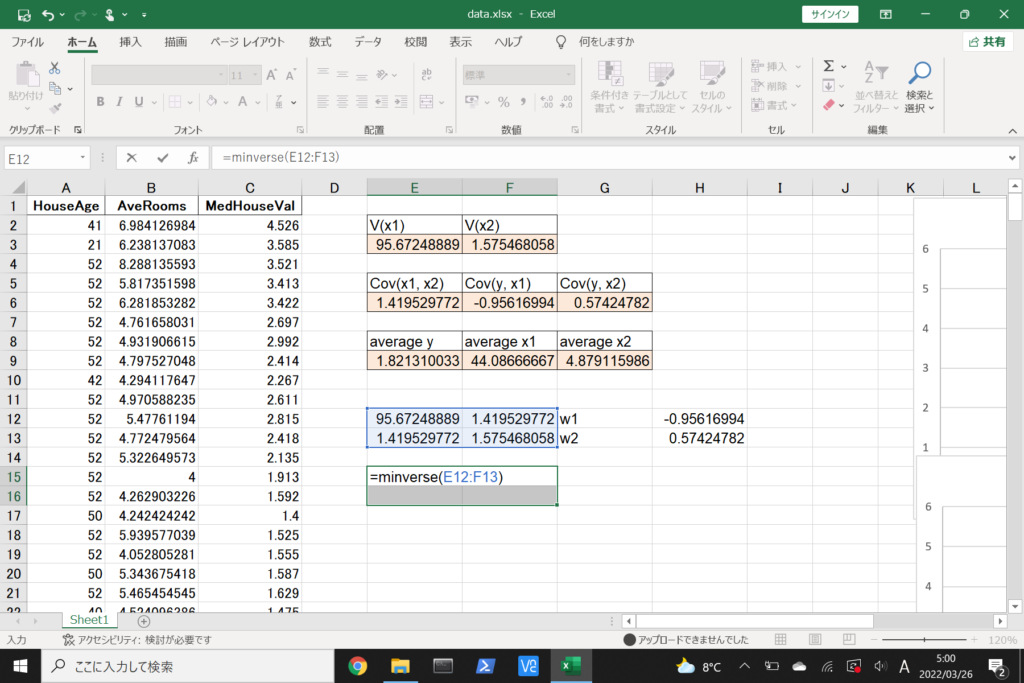

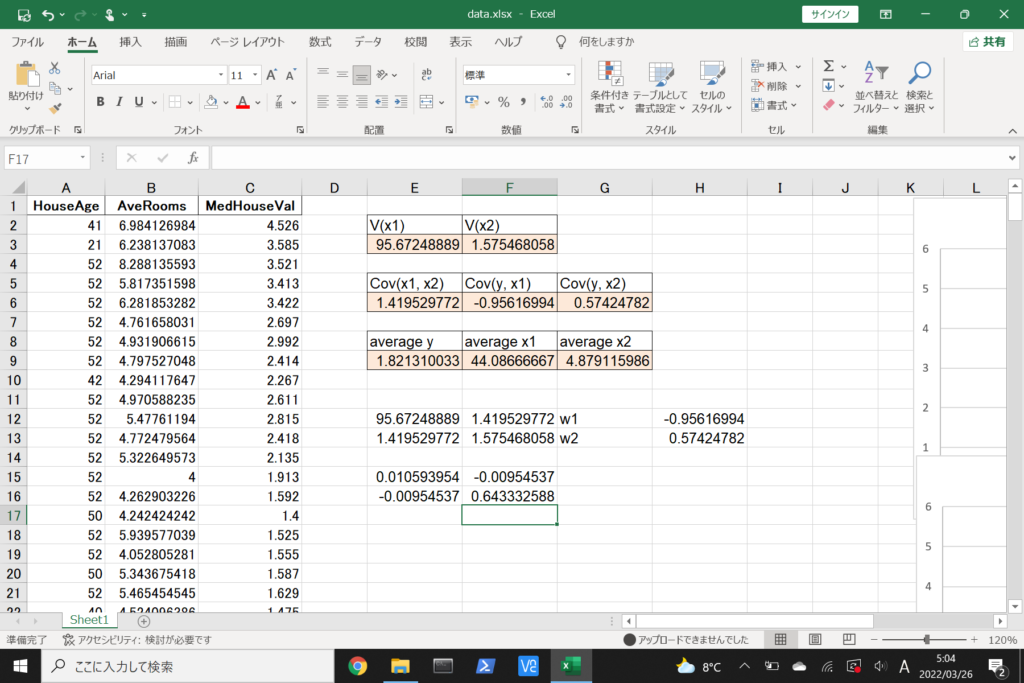

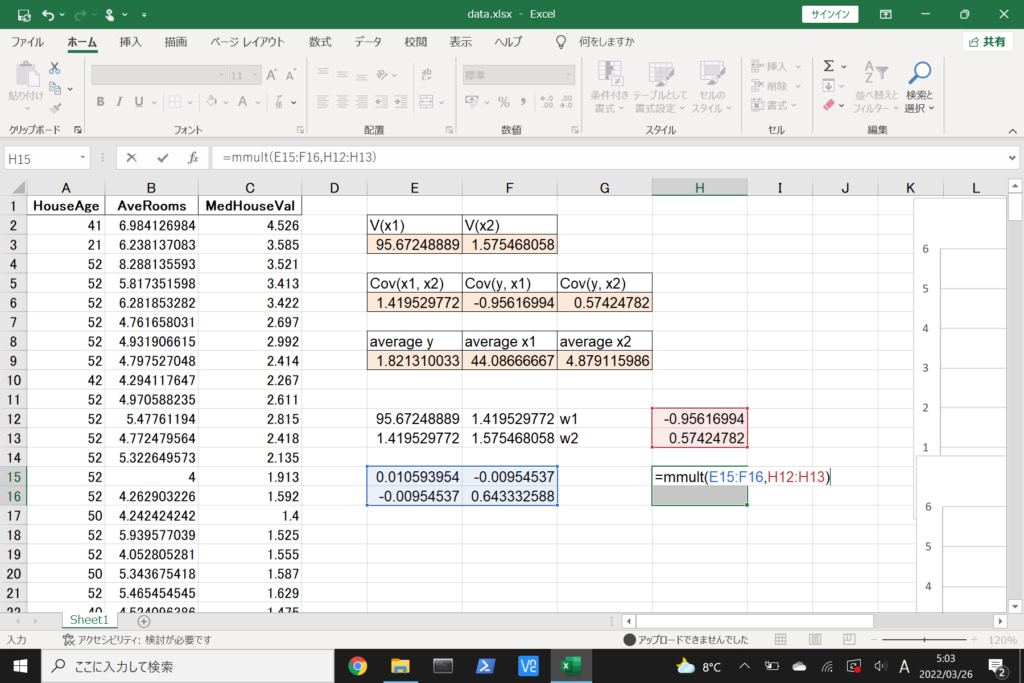


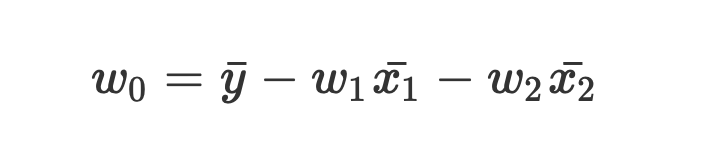

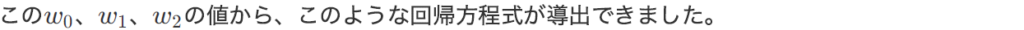


エクセルで重回帰分析(Windowsを使用)
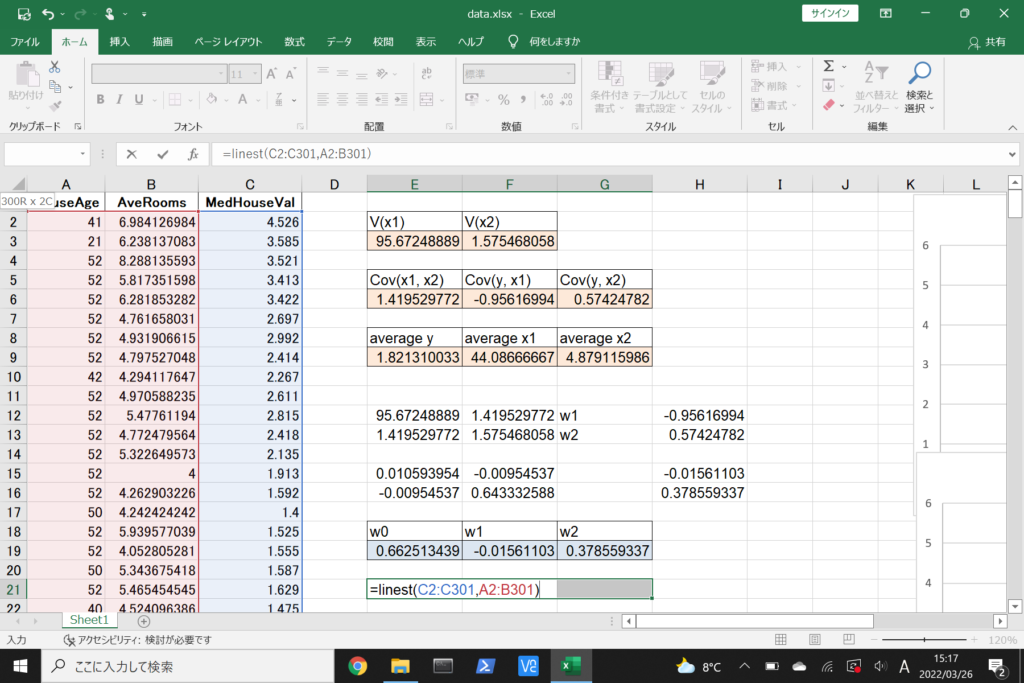
LINEST関数を使って回帰方程式を導出





まとめ

エクセルの関数の読み方の参考サイト
「ヘルプの森」 https://www.helpforest.com/excel/ex_list/ex110008.htm
