
この記事の執筆・監修

テクノロジーアンドデザインカンパニー株式会社のCEO。
日本最大級のプログラミング教育のYouTubeチャンネル「キノコード」や、プログラミング学習サービス「キノクエスト」を運営。
著書「あなたの仕事が一瞬で片付くPythonによる自動化仕事術」や、雑誌「日経ソフトウエア」や「シェルスクリプトマガジン」への寄稿など実績多数。
1.はじめに
こんにちは、KinoCodeです。
みなさんは、普段Excelでどのような業務をしていますか?
見積書や請求書、売上報告書、イベントの参加者リスト、スケジュールのメモ、住所録など、様々な用途がありますね。
今回は、Excelでデータ分析をする方法について説明します。
Excelでのデータ分析と一言で言っても、いくつか手法があります。
その中でも、Excelが初心者の方でも抵抗なく取り組めるような内容にしました。
ぜひご自身の業務に活かしていただければと思います。
KinoCodeでは、Excel脱初心者のためのExcel機能やグラフ、関数について説明した動画や、Excel作業をPythonで自動化する方法を解説した動画などを配信しています。
チャンネル登録と新着通知を忘れずにお願いします。
それでは、今回Excelで分析するテーマについて説明します。
使用するデータは、あるヨーロッパの銀行の、2008年から2010年の既存顧客のデータです。
このデータから、新規で定期預金の契約をしてくれそうな顧客を探す、というテーマです。
具体的に想像してみましょう。
あなたは、その銀行のデータ分析の担当者です。
営業マンから、どのように顧客にアプローチしたらよいかわからない、と相談がありました。
顧客データの上から順にアプローチをしていては、コストがかかるだけです。
できるだけ、効率的に新規契約を獲得する方法はないのでしょうか。
そこで、データを分析し、どのような顧客にアプローチをすればよいかを探ってみましょう。
ゆっくりと説明をしますので、実際に手を動かして試してみてください。
使用するデータは、KonoCodeのWebサイトからダウンロードができます。
概要欄にURLを記載しますので、ダウンロードして、ご自由にお使いください。
それではレッスンスタートです!
レッスンで使用したファイルはこちら
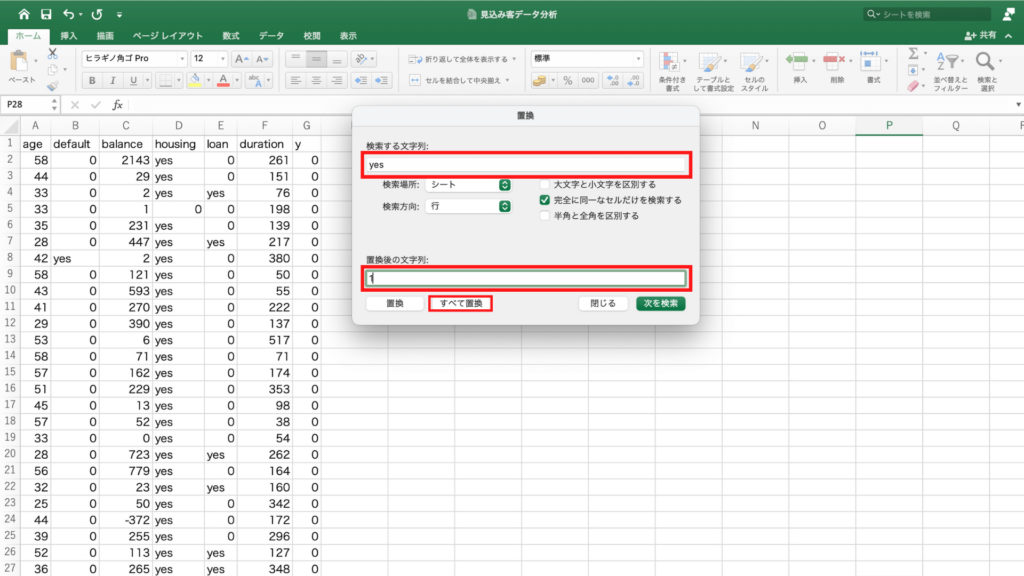
キノクエストでアカウントの新規登録に進み、メール認証を完了します。
ログインした状態(プラン選択画面が表示されます)で下記のボタンをクリックしてください。
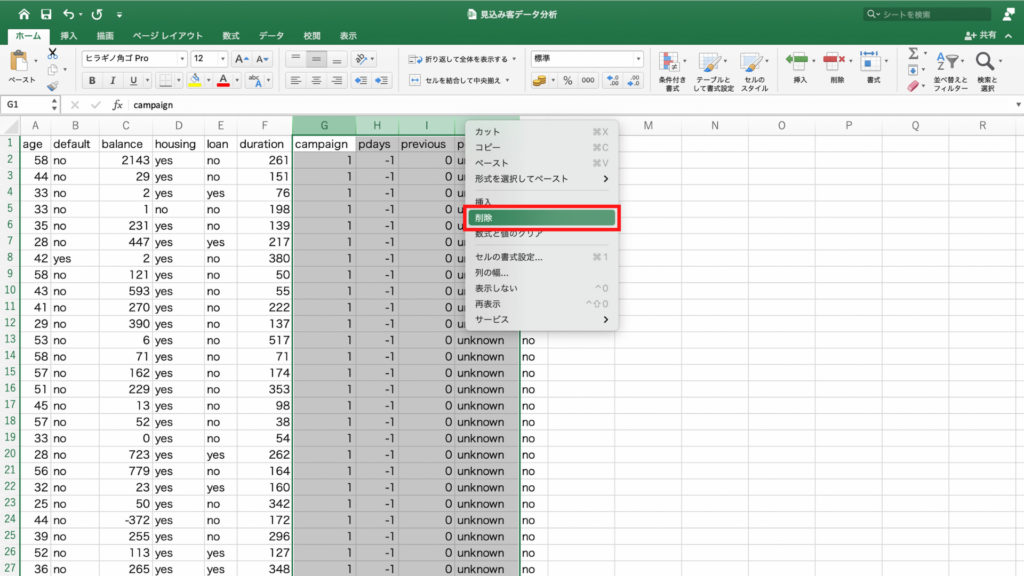
2. エクセルへcsvファイルを読み込む
2-1.csvファイルとは?
まず最初に「train_data.csv」というデータをエクセルに読み込みます。
今回使うデータはcsvファイルに保存されていますのでcsvファイル形式について説明をします。
結論から言うと、csvファイルとは「互換性が高く、データの受け渡しがしやすい」という大きなメリットがあるテキストファイルです。
「csvファイはテキストファイルである」ということを覚えておきしょう。
実務でもcsvファイルにデータを保存しているケースが数多くあります。
csvファイルの「csv」とは "Comma Separated Values"の略で「カンマで区切られた値」という意味を表します。
カンマだけでなくセミコロン「;」で区切られている場合もあります。
このようにcsvファイルには、カンマやセミコロンで区切られた値がテキストデータが収められています。
またcsvファイルと似たものに「tsvファイル」というものもあります。
tsvファイルはデータとデータの間が「tab」で区切られているファイル形式のことです。
「tab」はカンマやセミコロンのように表示はされませんが、「実際にはデータとデータの間に「tab」が入っています。

「カンマやセミコロンで区切られているもの」がcsvファイル、「タブで区切られているもの」がtsvファイルと覚えておくと良いでしょう。
では実際に今回使用するcsvファイルを開いて中身を確認してみましょう。

一見、とても見にくいのですが、文字列がカンマで区切られていることが確認できます。
csvファイルは人の目にはとても見づらいファイルですが、コンピューターにとっては「さまざまなソフトやシステムに容易に読み込みができる」というメリットがあります。
ちなみにデータを読み込むことを「インポート」と言いますので、こちらも覚えておきましょう。
csvファイルはエクセルにインポートできるだけでなく、その他のソフトやシステムにもデータを容易にインポートできます。
実務では顧客分析だけではなく、売上管理や勤怠管理などにも利用されています。
ここでもし各企業がデータをエクセル形式のファイルに保存していた場合、いったいどうなるでしょうか?
新しいソフトやシステムを導入した時に、もしかしたらスムーズにデータをインポートできないかもしれません。
また相手企業とデータを共有する際、そもそも相手側がエクセルを使っていなければ、簡単にデータを共有することができないかもしれません。
もし相手がエクセルを使っていてもバージョンの違いで不具合が出る場合もあります。
このようにエクセル形式は互換性やデータの受け渡しの点で問題を生じる恐れがあります。
その点、csvファイル形式はエクセル形式に比べて「互換性が高くデータの受け渡しがしやすい」ため、いろいろな場面で使われています。
2-2.エクセルへcsvファイルを読み込み方法
では実際にエクセルにcsvファイルをインポートしてみます。
まずエクセルを開きます。
空(から)のファイルを開いたことが確認できたら、ファイル名を「見込み客データ分析」と名前を付けて保存します。
「ファイル」から「名前をつけて保存」を選択します。
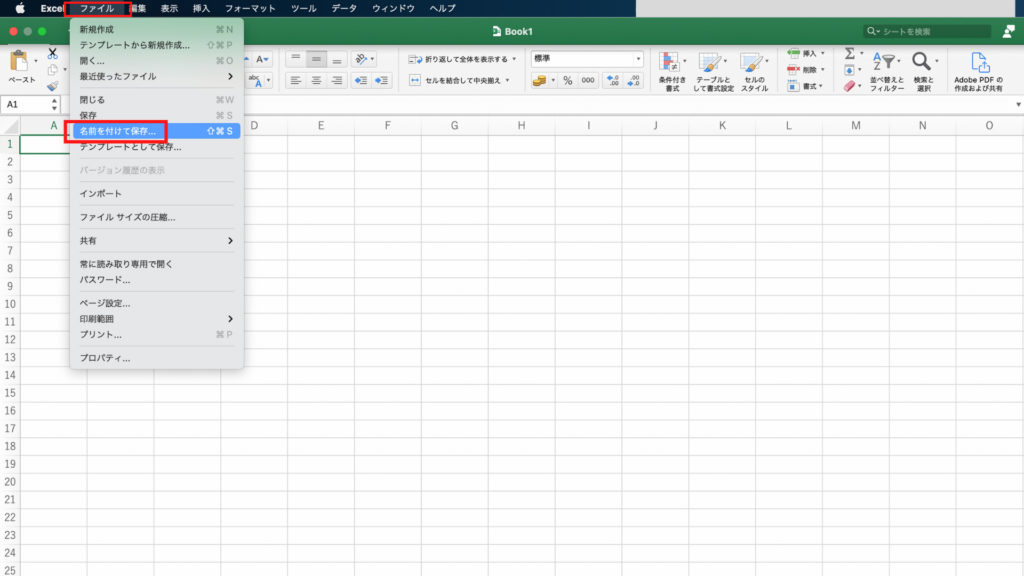
「名前」に「見込み客データ分析」と入力し「保存」をクリック。
ファイル名が「見込み客データ分析」になりました。
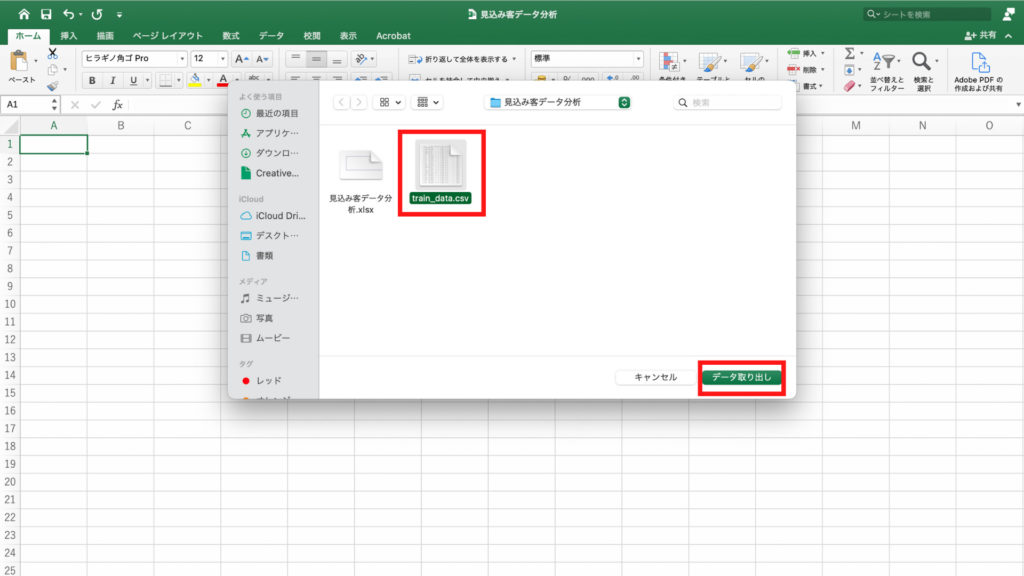
次に「train_data.csv」というファイルをインポートしていきます。
事前準備として、「train_data.csv」を「見込み客データ分析」のエクセルファイルと同じフォルダに置くと操作しやすいです。
「データ」から「外部データの取り込み」を選択し「テキストファイルのインポート」をクリックします。
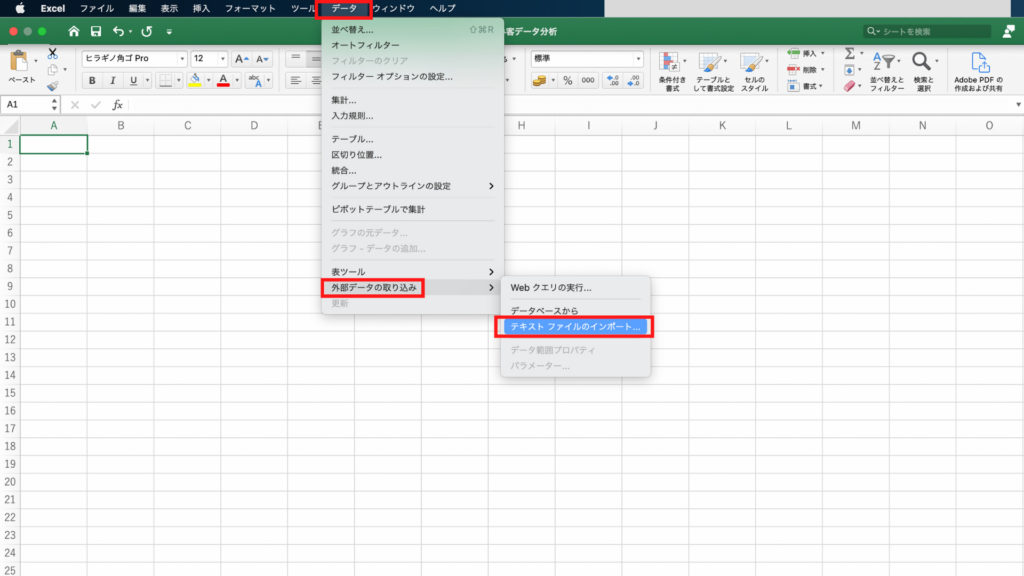
「train_data.csv」を選択し、「データ取り出し」をクリックします。
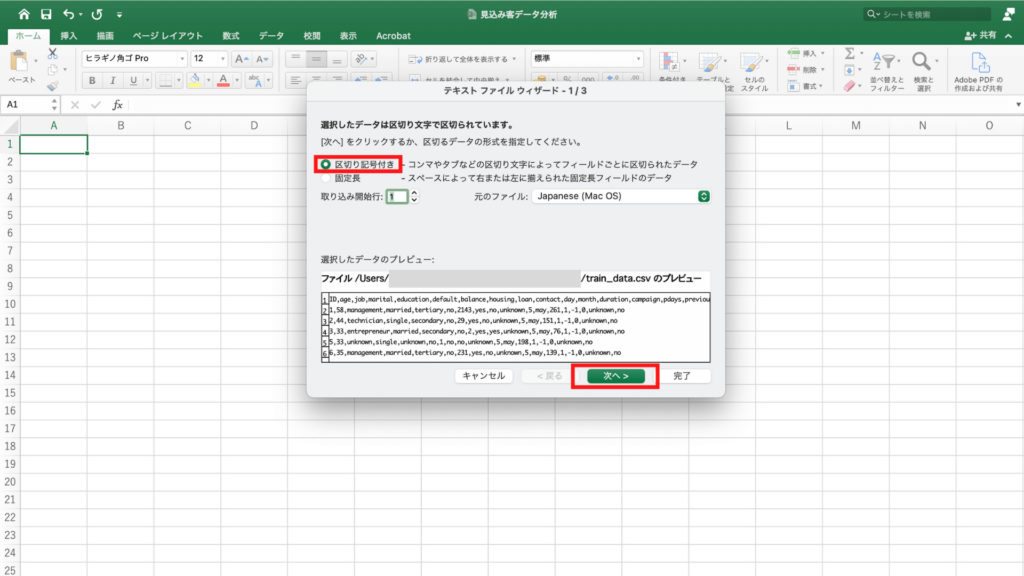
「テキスト ファイル ウィザード」が開きますので、「区切り記号付き」を選択します。
下のプレビューを見るとデータがカンマで区切られていることが確認できますので、確認をしたら「次へ」をクリック。
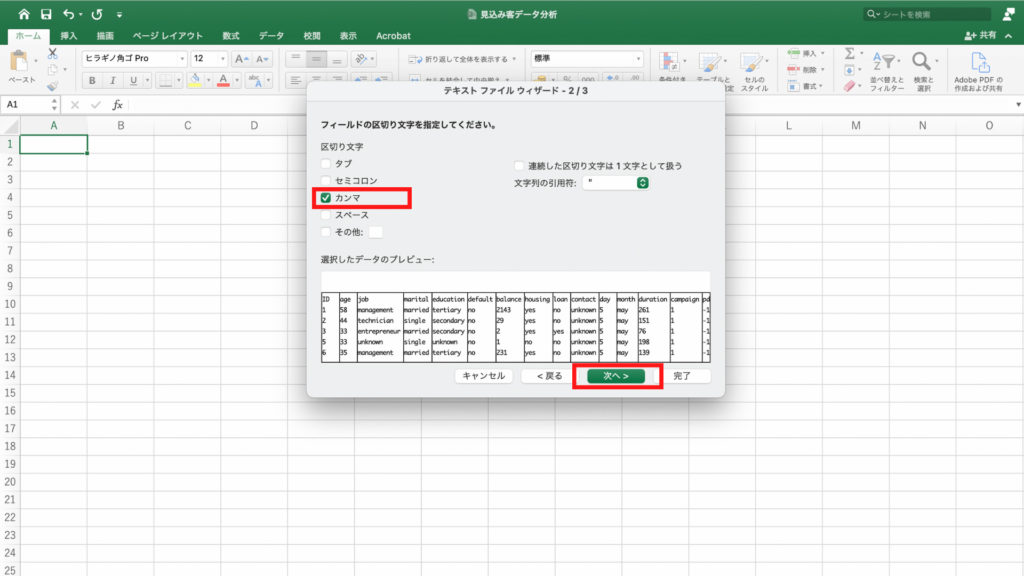
「フィールドの区切り文字をしてください」と表示されますので、「カンマ」を選択し「次へ」をクリック。
「区切ったあとの列のデータ形式を選択してください」と表示されますので、今回は「標準」を選んで「完了」をクリックします。
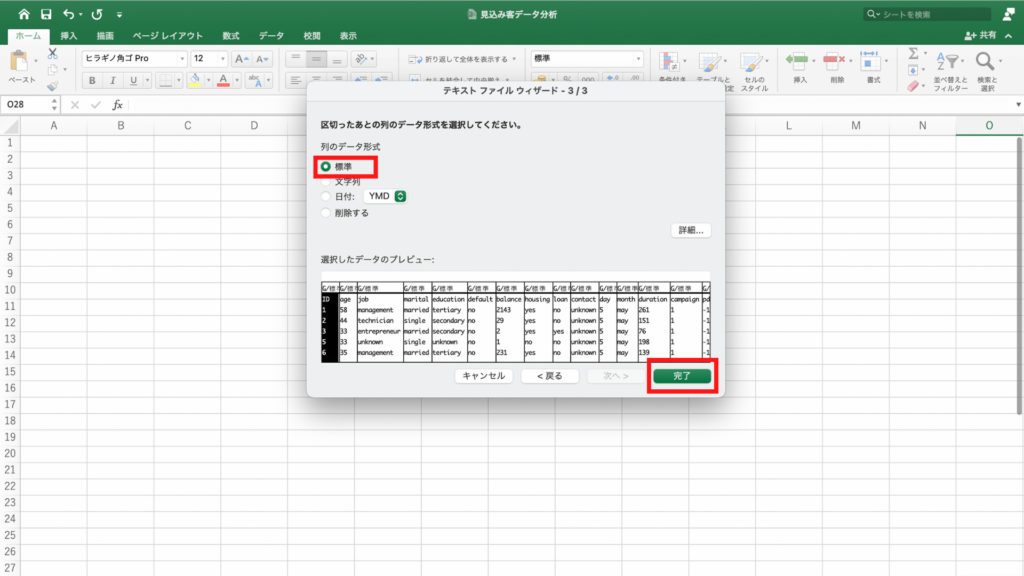
「データを返す先を選択してください」と聞かれるので、今回は「既存のシート」を選択し「OK」をクリックします。
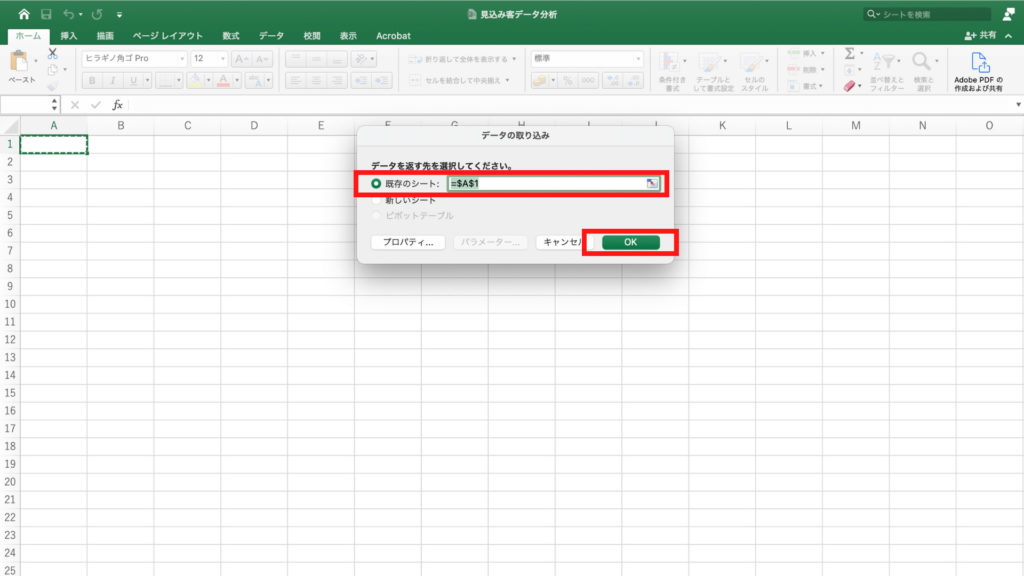
これで「train_data.csv」のデータをエクセルにインポートすることができました。
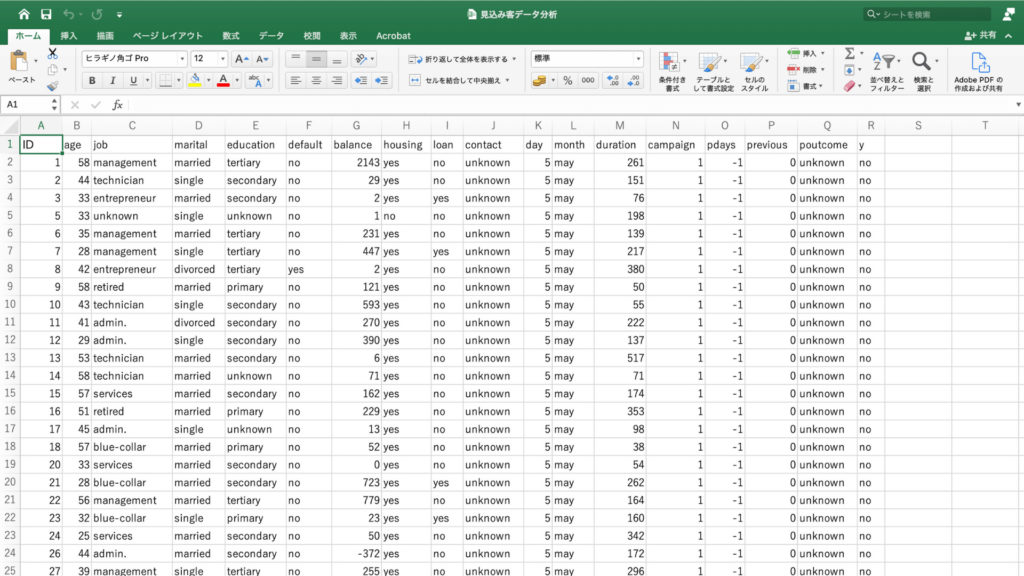
2-3.エクセルにインポートしたデータを確認する
次にざっとインポートしたデータの大枠を確認しましょう。
ここでは主に欠損値がないかどうかの確認を行います。
欠損値とは記入漏れや自動集計システムの不具合などによってデータが取れなかった場合にデータが欠落しているものを指します。
アンケート集計の場合は、無回答の場合も欠損値になります。
本来、欠損値があるデータは、そのままでは機械処理できないので、何らかの方法で欠損値を埋めたり除去するなどの処理が必要です。
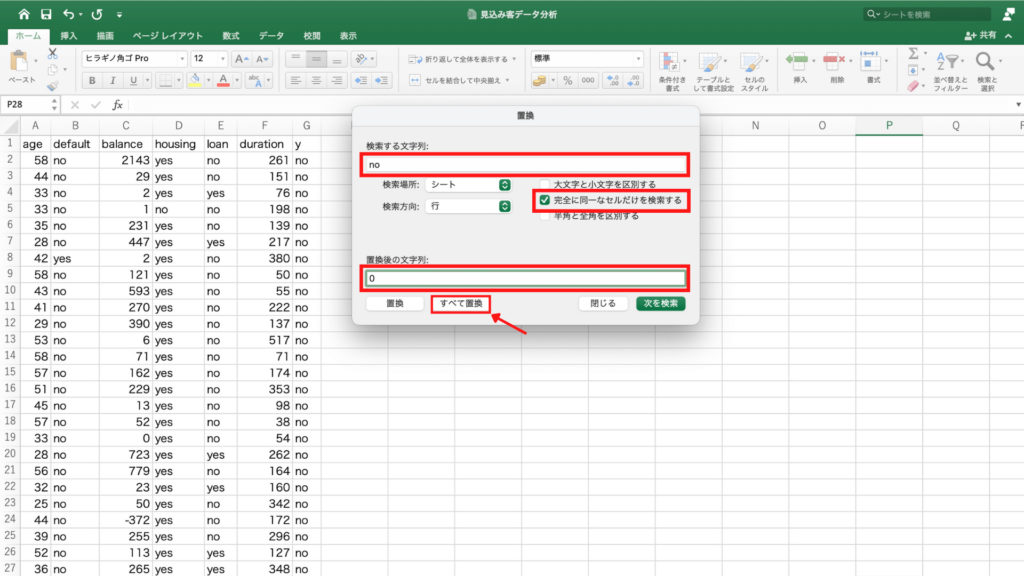
しかしながら今回のデータは、すでに欠損値に処理が施されています。
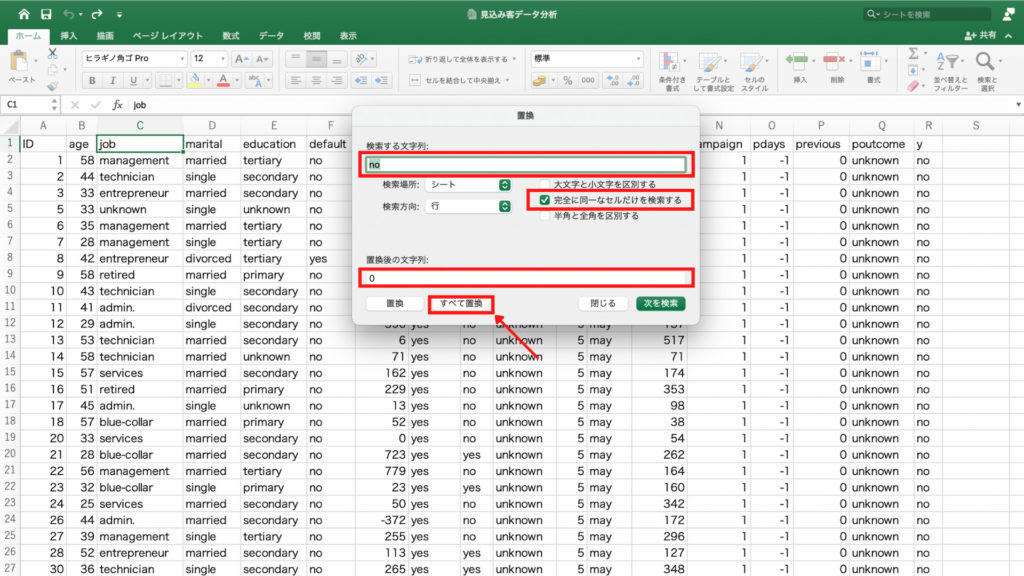
具体的には「unknown」という文字で補完されていたり、「-1」という数値で補完されています。
詳細は省略しますが、今回はとくに欠損値の処理がありませんので、そのまま次のステップに進みます。
2-4.各項目の意味を確認する
まず最初に与えられた顧客データに含まれている項目の意味を把握します。
英語で書かれていますが、日本語では次のような意味です。
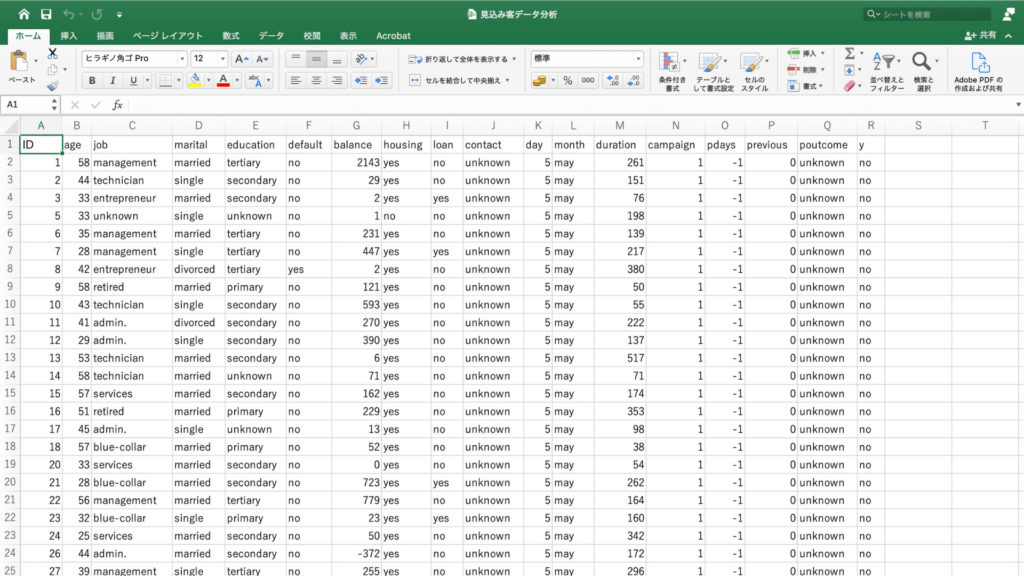
左からID、年齢、職業、婚姻状態、教育水準、債務不履行の有無、口座残高、住宅ローンの有無、個人向けローンの有無、連絡方法、最終接触日、最終接触月、最終接触時間、前回のキャンペーンにおける接触回数、前回のキャンペーンで接触した時からの経過日数、今回のキャンペーン以前に接触した回数、前回キャンペーンの成果、そしてyが定期預金の申し込みの有無です。
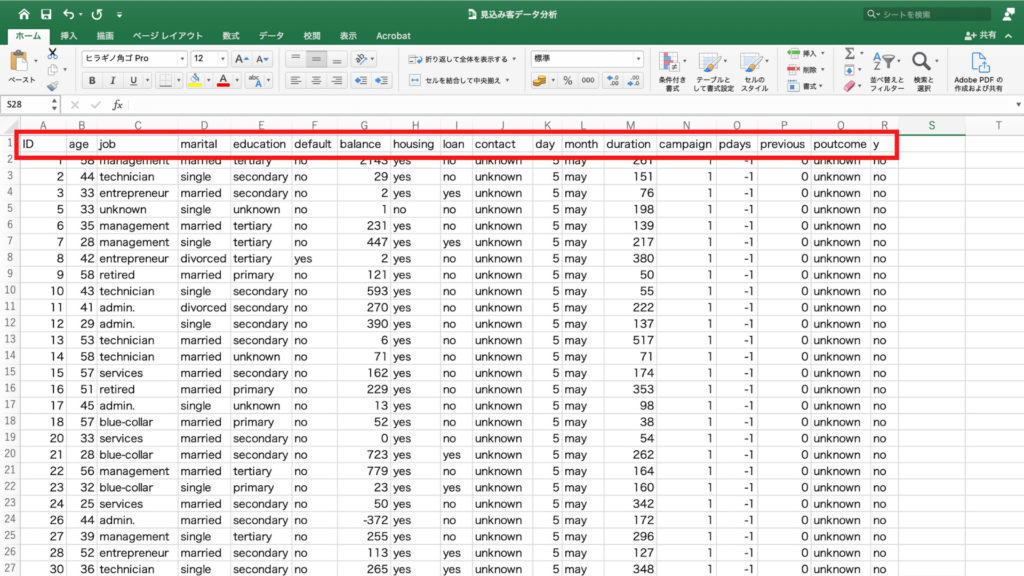
今回のデータに含まれている項目をまとめたものがこちらです。
IDを含めて18個の項目が確認できました。
お気付きのように今回のデータには定期預金の申し込みの有無まで含まれています。
「y」の「定期預金の申し込みの有無」というのは、いわば今回の課題の「答え」です。
そして「答え」を持っているデータのことを教師データと呼びます。
実務ではこの教師データをもとに、今後アプローチする顧客に対して「いったいどのような属性を持つ顧客から優先的にアプローチしていけばよいのか?」ということを予測します。
2-5.データには数値と文字の2種類があることを確認する
データをご覧いただいてお分かりいただけるように、データには大きく分けて2種類のデータがあります。
「数値で表されるデータ」と「文字で表されるデータ」です。
年齢や口座残高、最終接触時間のような「数値で表現されるデータ」と、職業や婚姻状況、教育水準のように「文字で表現されるデータ」が確認できます。
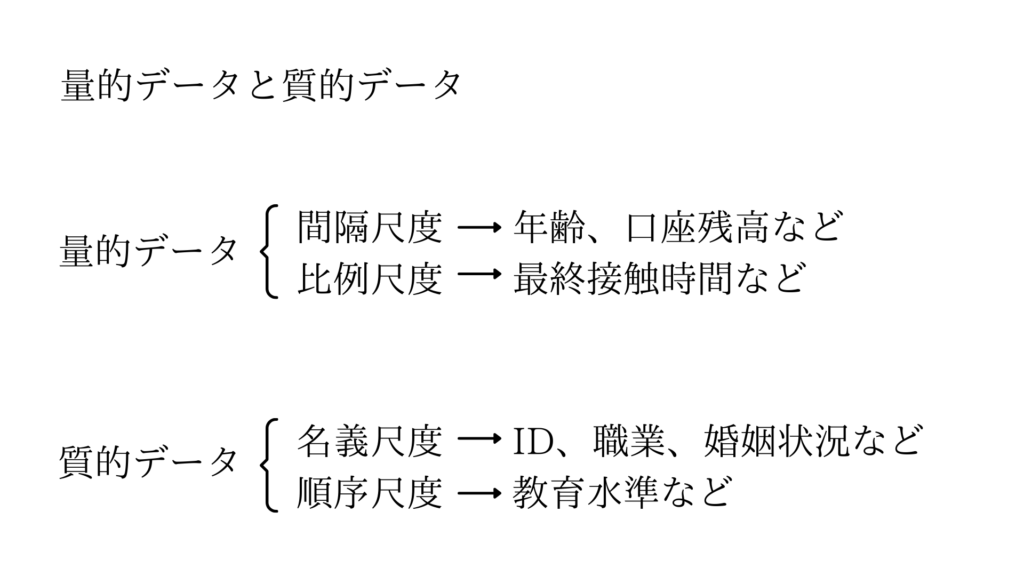
数値で表現されるデータのことを「量的データ」、文字で表現されるデータのことを「質的データ」と呼びます。
別の言い方として「数値データ」「カテゴリデータ」と呼ぶこともあります。

量的データはさらに間隔尺度と比例尺度に分かれます。
間隔尺度とは目盛りが等間隔になっているもので、今回の場合では「口座残高」が該当します。
比例尺度とは間隔と比例に意味があるもので、今回の場合では「最終接触時間」が該当します。
そして間隔尺度と比例尺度はよく似ているので明確に分類するのは難しいのですが、比例尺度は0のような原点があるのが特徴です。
例えば、口座残高が0というのは原点ではなく、「貯金も借り入れもない」と言う状態を表します。
仮に口座残高が多ければ定期預金を契約してくれると言う期待ができる一方で、マイナスになると「借り入れがある」という状態を表し、定期預金の契約はあまり期待できないという意味があります。
一方、最終接触時間が0の場合は「全く接触がない」という状態を表し、接触時間が多ければ、定期預金の契約に結びつくという期待できます。
接触時間がマイナスということは現実的にはありえないため、0から始まるという点で原点があると言えます。
また質的データの名義尺度と順序尺度に分かれます。
今回のデータでの名義尺度は「ID、職業、婚姻状況」です。
とくにIDや職業、婚姻状況に優劣はありません。
しかし「教育水準」は中卒、高卒、大卒のように一般的には収入面に優劣がつきやすいのため順序尺度に分類しました。
今回はそういう分類があるということを参考として知っていただく程度で問題ありません。
3. 探索的データ分析(EDA)を行う
インポートしたデータの大枠が確認できたら、次はいよいよデータ分析を行います。
データ分析の基本は「データを分解し比較すること」です。
与えられたデータを分解し比較することによって、どのようにデータを使えば課題の解決につながるかを探索します。
これを「探索的データ分析」といい、英語の「Exploratory Data Analysis」の頭文字を取って、「EDA」と呼ばれています。

EDAは重要で、与えられたデータ全体を眺めたり可視化したりしながら、課題の解決につながりそうな仮説を立て検証していきます。
例えば、今回は新たに定期預金の契約をしてくれそうな顧客を見つけ出すことが課題になっていますので、「お金をたくさん持っている人のほうが契約をしてくれるのではないか?」や「職業が定期預金の契約に関係するのではないか?」などの仮説を立てることができます。
そしてこれらの仮説に対して、実際にデータを分解し、比較しながら、課題の解決につながるかどうかを検証します。
3-1. 基本統計量の確認
そしてここからが本格的なEDAの方法です。
EDAの方法は大きく分けて「基本統計量の確認」と「可視化」があります。
まずは数値データの基本統計量を見ていきましょう。
しかし今回のデータはあまりに多いためか、パソコンの画面に収まり切っていません。
このような場合は、列を選択すると、その項⽬に⼊っているデータの情報を確認できます。
実際にやってみましょう。
今回は例として「age」の項目を見ます。
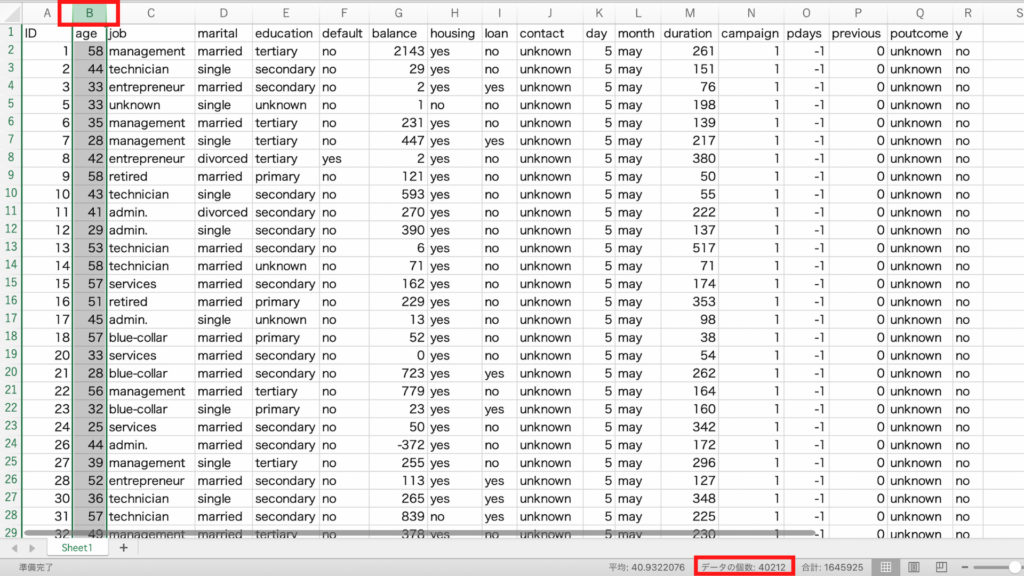
「age」はエクセルのB列に格納されていますので、アルファベットの「B」をクリックします。
するとB列全体が選択されました。
そして画面の下を見てください。
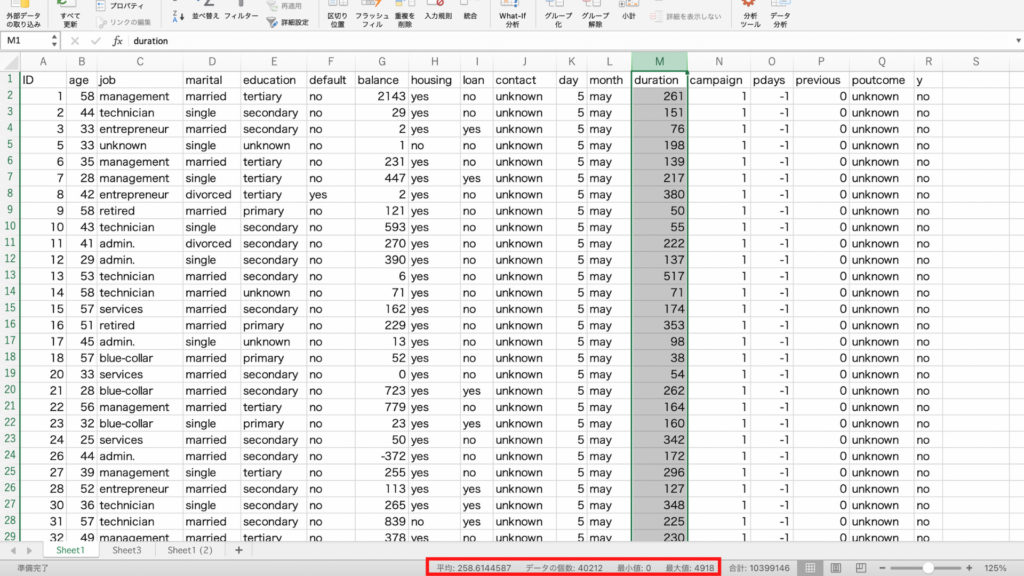
平均とデータの個数、合計が確認できます。
今回の場合、データの個数は40212個で、見出しの1行目を差し引くと40211個あることがわかります。
ちなみにエクセル画面下側の「データの個数」が表示されている枠の部分を「ステータスバー」と呼びます。
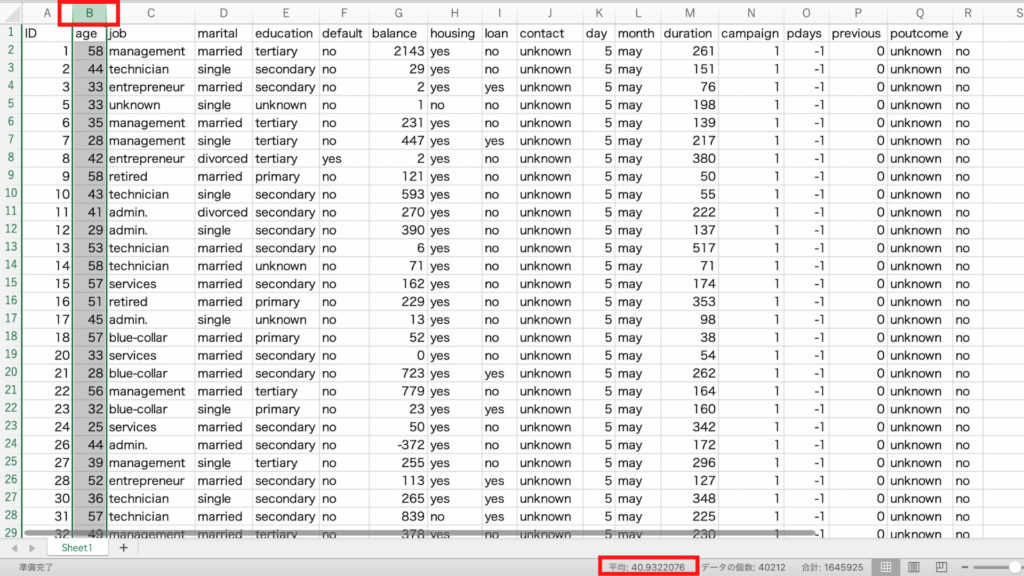
続いてステータスバーで、データの平均も確認します。
さきほどの「データの個数」の左側に、「平均」が表示されています。
今回のデータでは顧客の平均年齢が約41才だということがわかります。
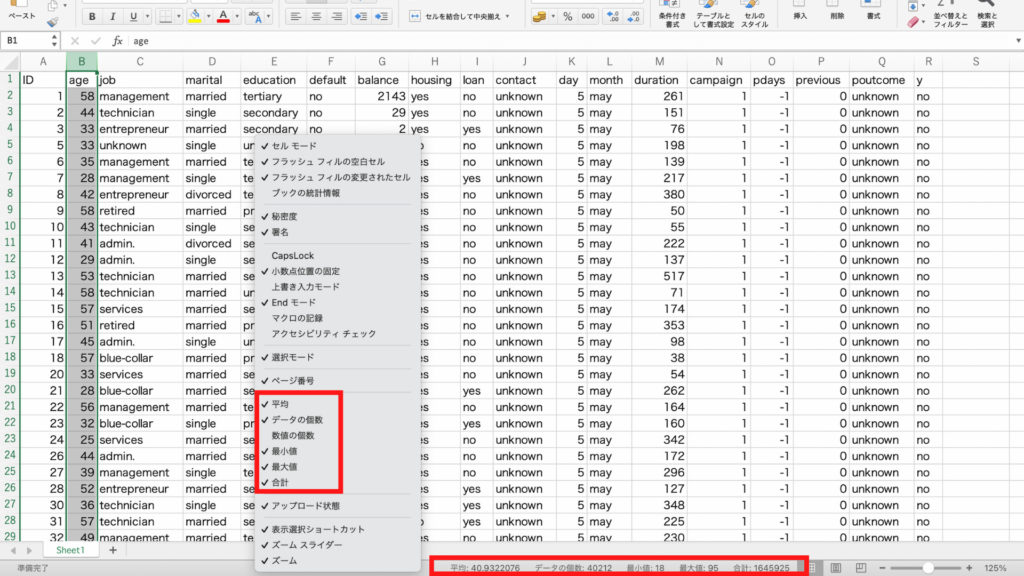
ほかにもステータスバーでは最小値や最大値などを確認することもできます。
ステータスバーを右クリックしてみましょう。
すると平均やデータの個数だけでなく、最小値や最大値も選択することができます。
見たいものにチェックを入れると、チェックされたものがステータスバーに表示されました。
エクセルでは、さらに詳しい基本統計量をみることができます。
実際に、年齢の基本統計量を見ていきましょう。
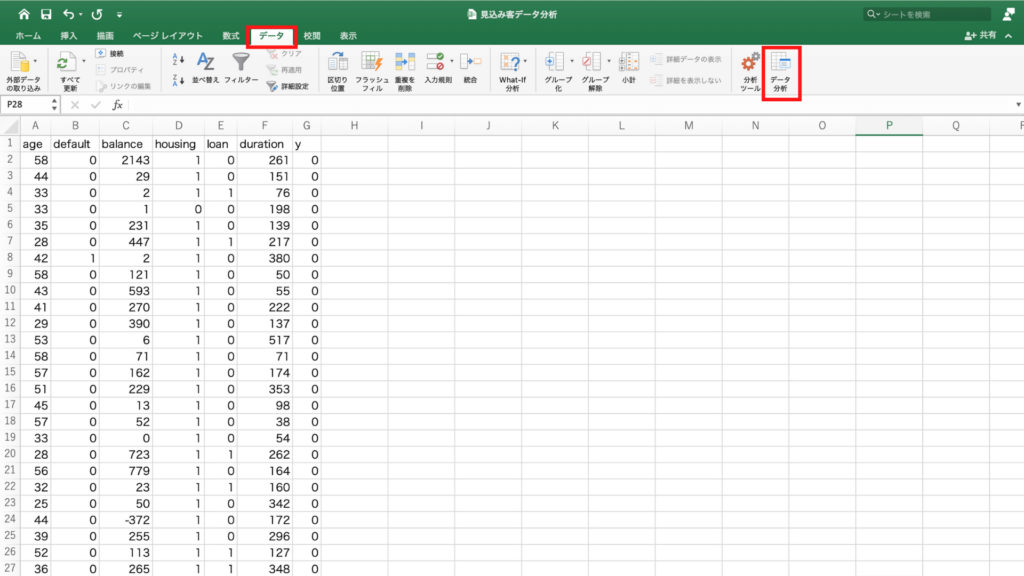
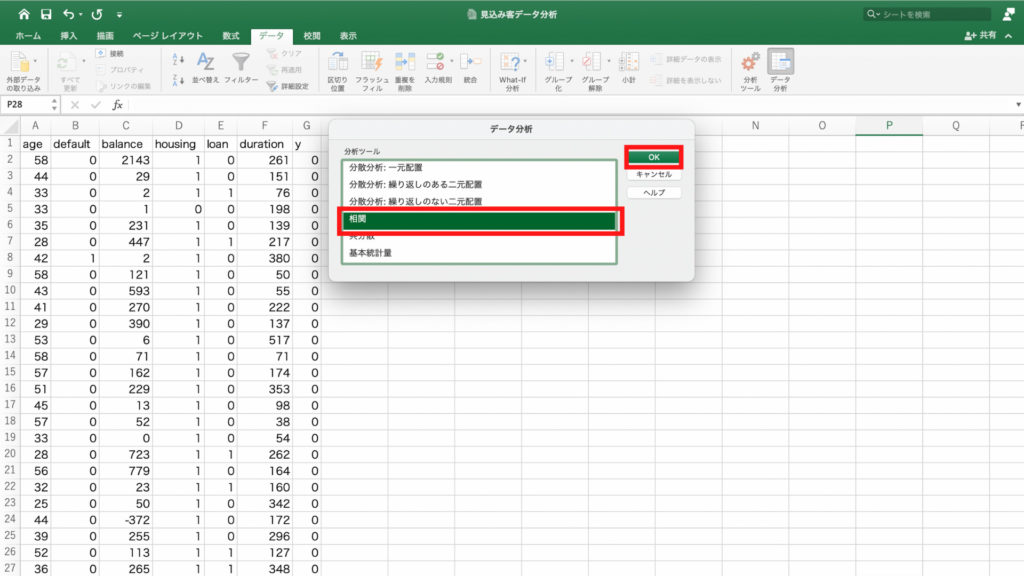
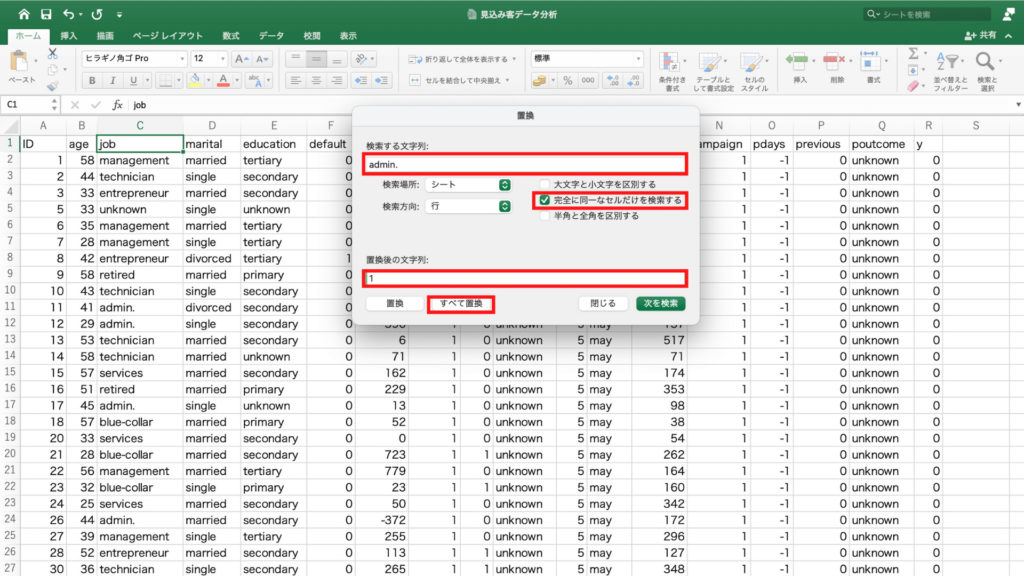
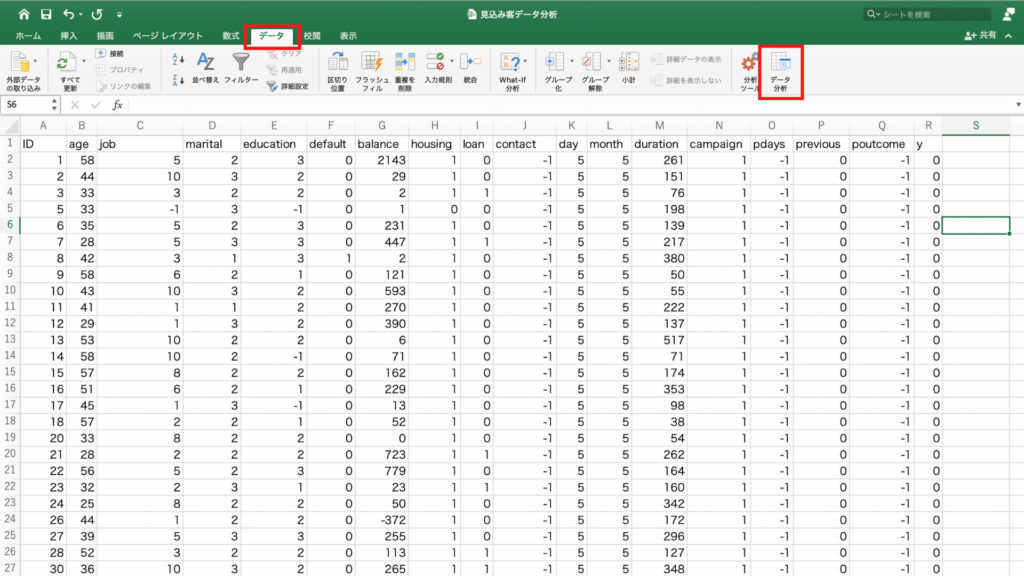
「データ」タブをクリックし、「分析ツール」をクリックします。
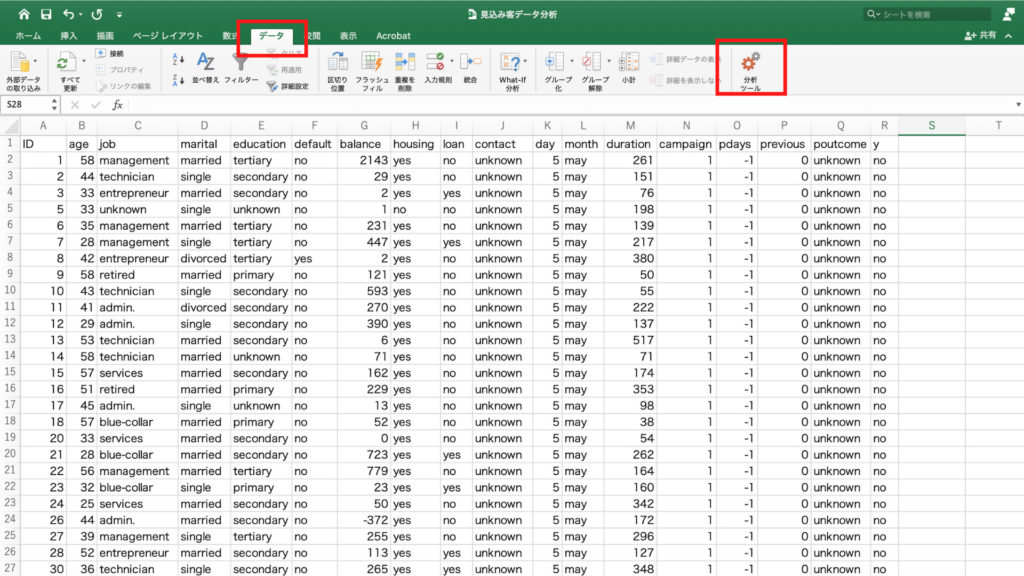
「有効なアドイン」で「分析ツール」を選択し「OK」。
先程の「分析ツール」のアイコンの隣に「データ分析」というアイコンができますので、これをクリック。
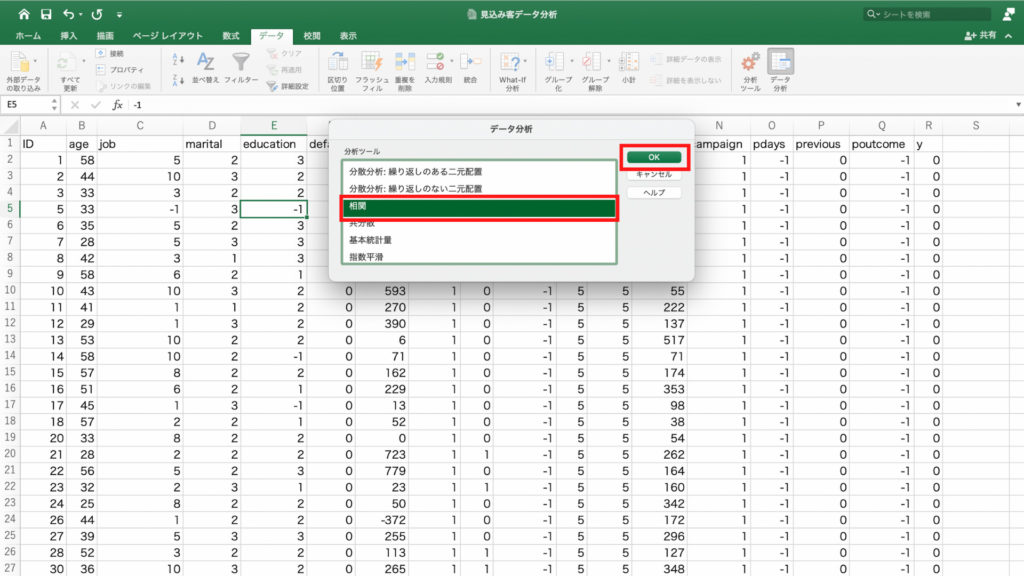
分析ツールの中から「基本統計量」を選択してOKをクリックします。
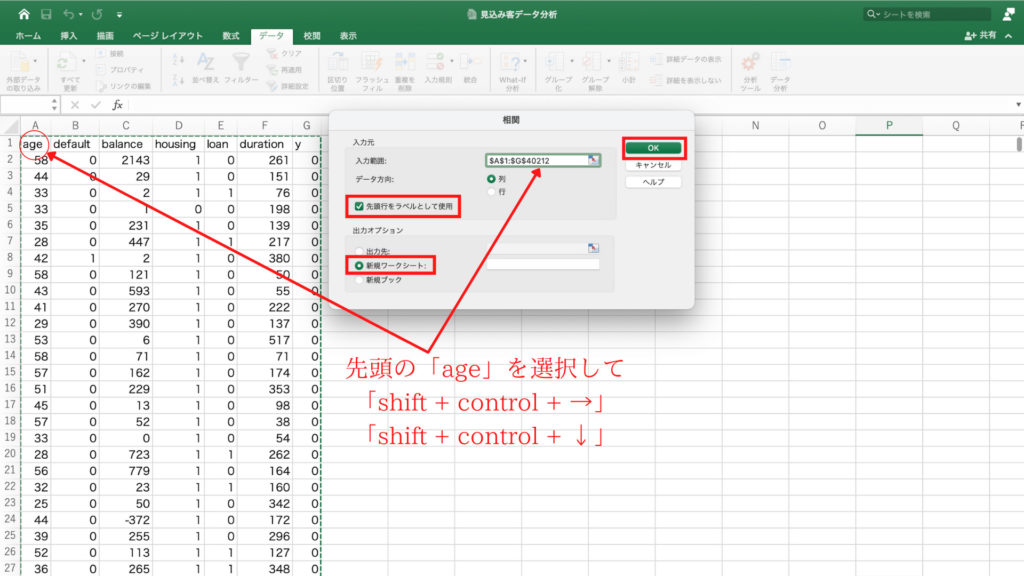
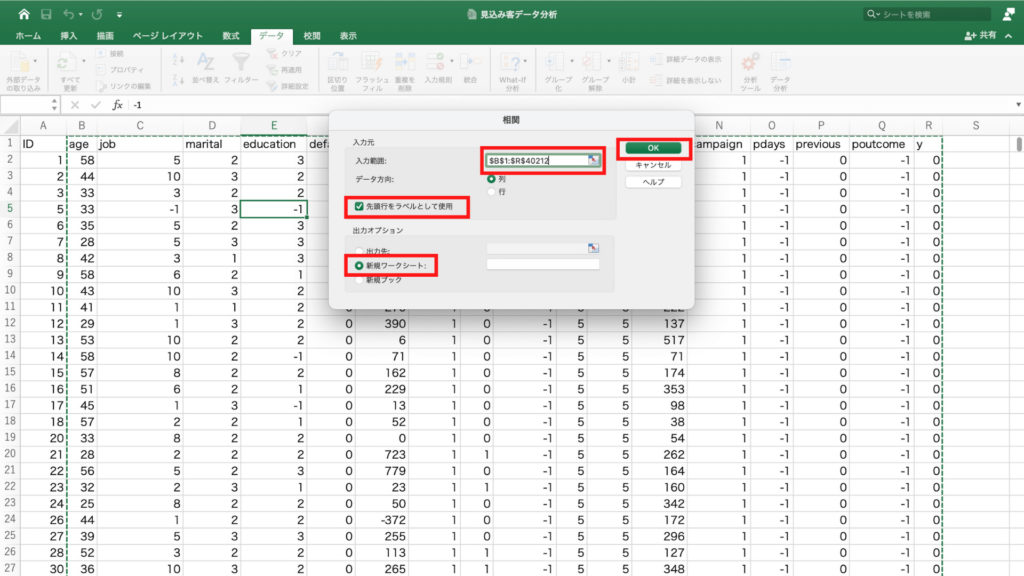
「統計情報」にチェックを入れて、範囲を指定します。
今回は age の統計情報を確認したいので、age列のデータの先頭をクリック。
今回の場合はB2のセルです。
情報統計は文字列には使えませんので、誤って見出しであるB1の age という文字列を含まないようにすることに注意が必要です。
age列の先頭のデータを選択したら、今度はデータの終わりを選択します。
しかし今回は40000以上のデータを含みますのでスクロールしてデータの終わりを探すことは現実的ではありません。
今回のような場合はデータの先頭のセルB2を選択した状態で「ctrl + shift + ↓」を押すと一瞬で下端までのデータが選択できます。
範囲が指定できたら「OK」を押します。
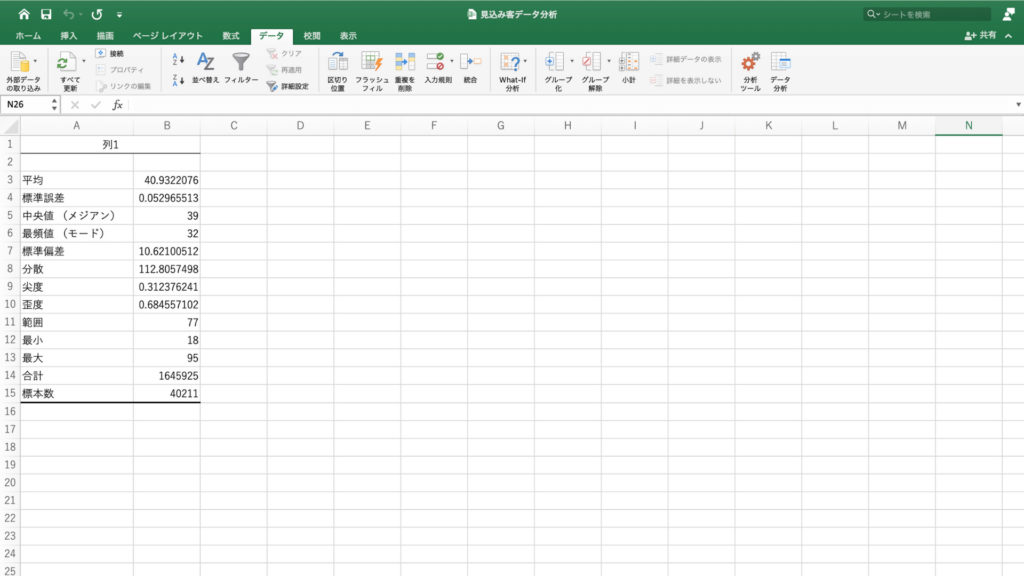
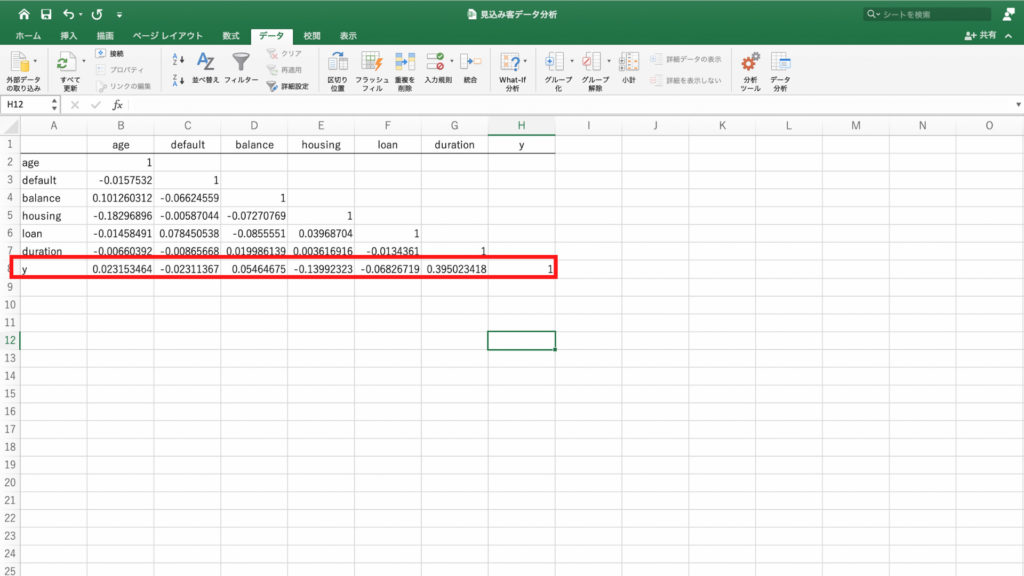
別シートに統計情報が表示されました。
平均値や中央値だけでなく、最小値や最大値、その他の値も確認できます。
年齢の基本統計からの平均は40.9才、中央値は39才、最頻値は32才、最小値は18才、最大値は95才ということがわかります。
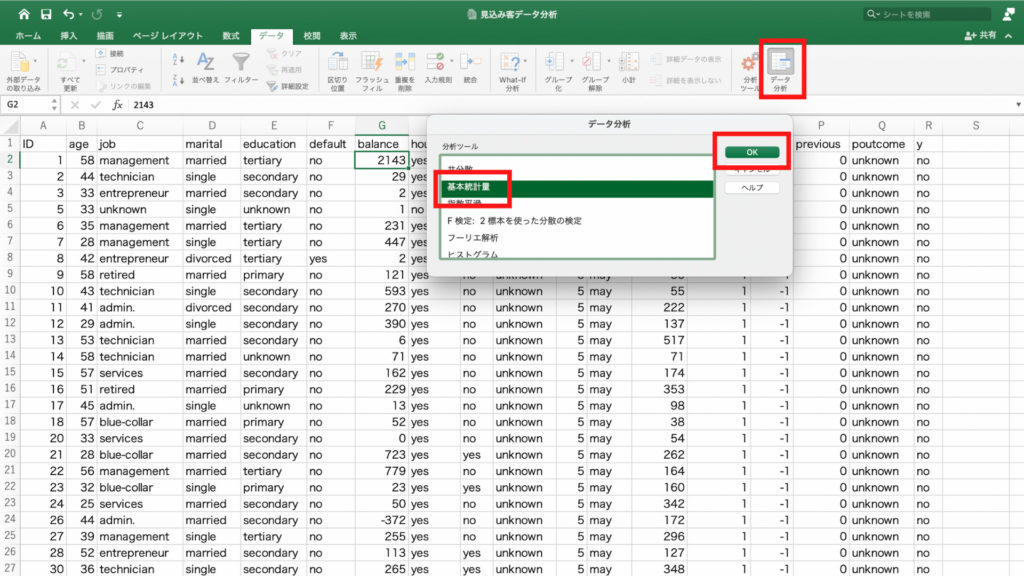
次に口座残高の基本統計量も見ていきます。
年齢の時と同じように、「データ分析」のアイコンをクリックします。
balance列の先頭のデータを選択し「基本統計量」を選んで「OK」。
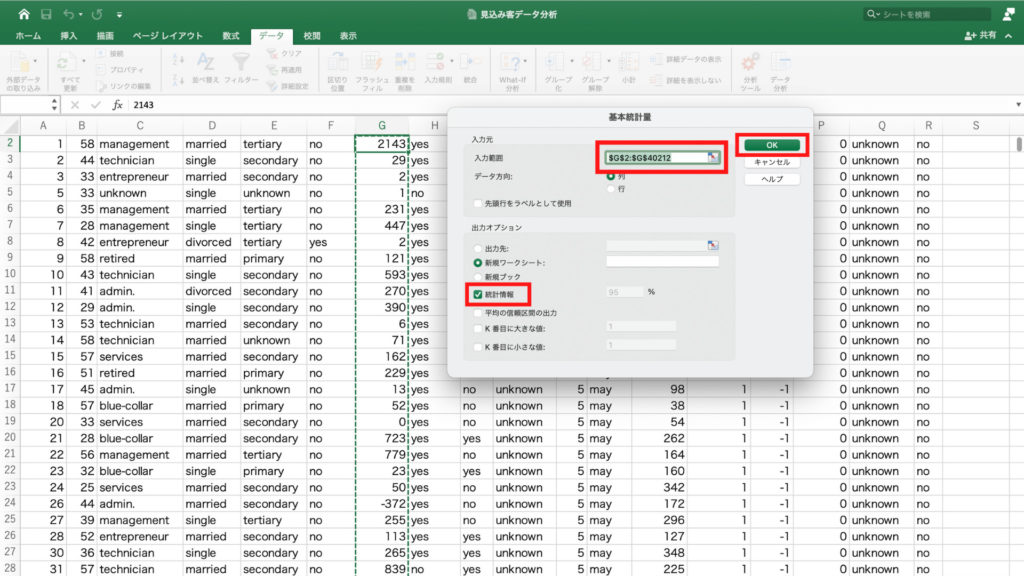
「ctrl + shift + ↓」で範囲を選択。
「統計情報」にチェックを入れて「OK」。
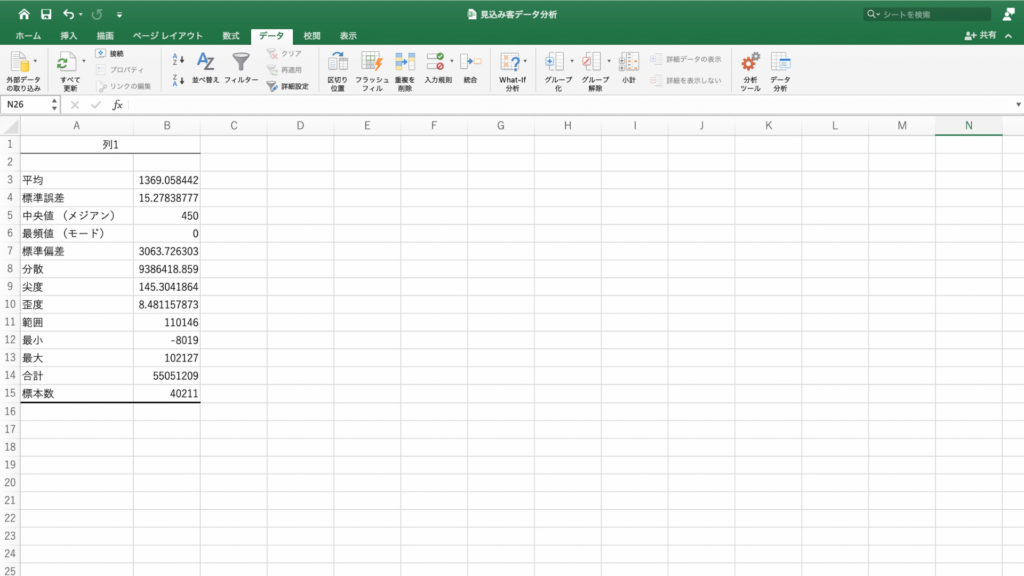
口座残高の統計情報が表示されました。
平均残高は1369ユーロ、中央値は450ユーロ、最小値が-8019ユーロで最大値が102,127ユーロということがわかります。
もうひとつ、最終接触時間も確認します。
最終接触時間の平均は258秒で約4分18秒です。
中央値は180秒で約3分です。
最大値は4918秒で約82分です。
最大値の人はかなり長い時間、いったい何を話していたのでしょうか?
少し気になりますが、問題はこの人のようなデータがたくさんあるかどうかを見極めることです。
1人だけならあまり気にしなくても良さそうですが、もしたくさんいるなら分析にも影響が出ますので念の為確認します。
ここでは箱ひげ図というもので確認をします。
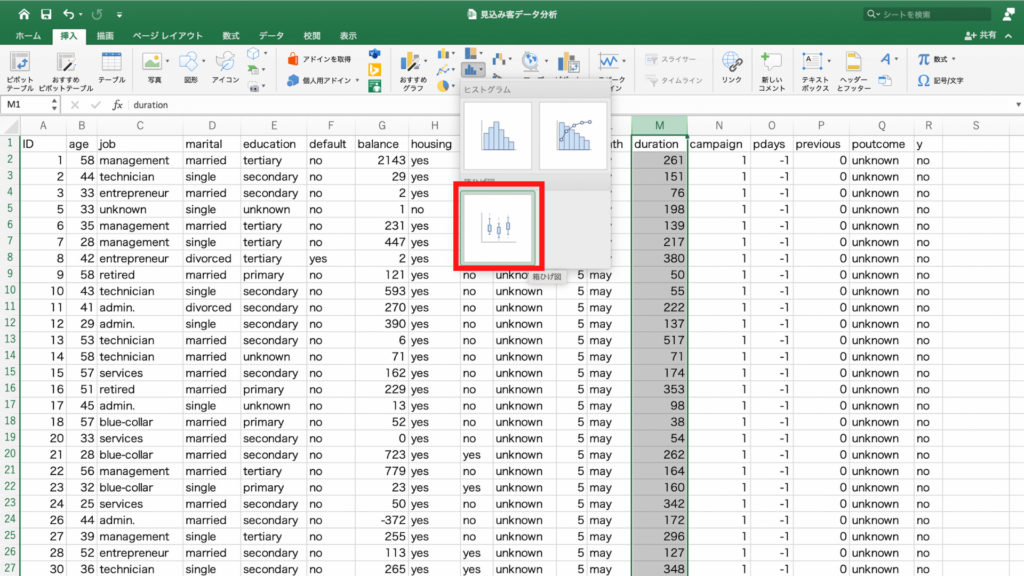
対象となる「duration」のデータを列を選んで「挿入」タブから「統計」のグラフを選択します。
この時にアイコンの横に小さな下向きの三角印がありますので、ここをクリックします。
するとヒストグラムと書かれた枠の下に「箱ひげ図」のアイコンが出ますので、これをクリック。
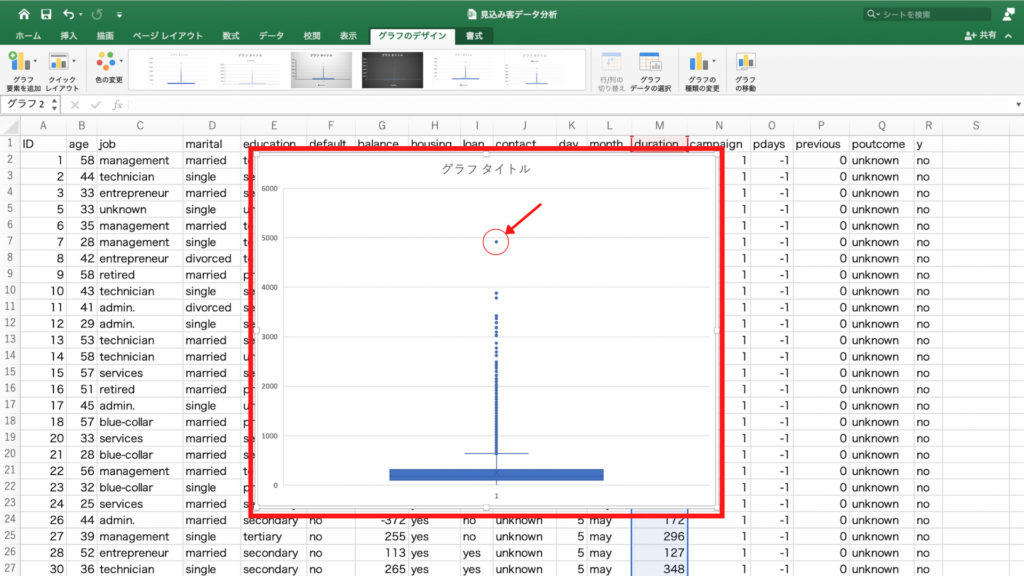
箱ひげ図が表示されました。
多くの人が500秒未満なのに対して、最大値の人はポツンと離れたところにデータがあります。
これがもし記録ミスや何かのミスであれば「異常値」となります。
もしこれがただの長話しであれば「外れ値」として扱います。
異常値であれば本来あってはいけないデータのため削除するなどの処理をしても良いのですが、外れ値であれば、実際のデータでなので、そのまま削除するのは得策ではありません。
実務では外れ値に対しては標準偏差を取るなどの処理の仕方がありますが、今回は特に何も処理せずに話を進めます。
3-2.可視化
さきほど箱ひげ図を見てきましたが、可視化とはグラフを用いて視覚的にデータを捉えることができるようにすることです。
可視化をすると直感的にデータを把握できる上に、エクセルでは簡単にグラフを作ることができるので大変便利です。
ここからはデータ分析に欠かせないピボットテーブルを使っていきます。
ピボットテーブルは数式や関数を入力する必要がなく、マウスのドラッグ&ドロップとクリックだけで操作できるので初心者でも非常に使いやすいです。
それでは早速ピボットテーブルを使ってみましょう。
まず「挿入」タブを開き「ピボットテーブル」をクリックします。
するとピボットテーブルを作成する範囲が自動で選択されます。
ピボットテーブルの作成先に「新規ワークシート」を選択し「OK」をクリック。
すると画面左側に「ピボットテーブル」、画面右側に「ピボットテーブルのフィールド」が作成されます。
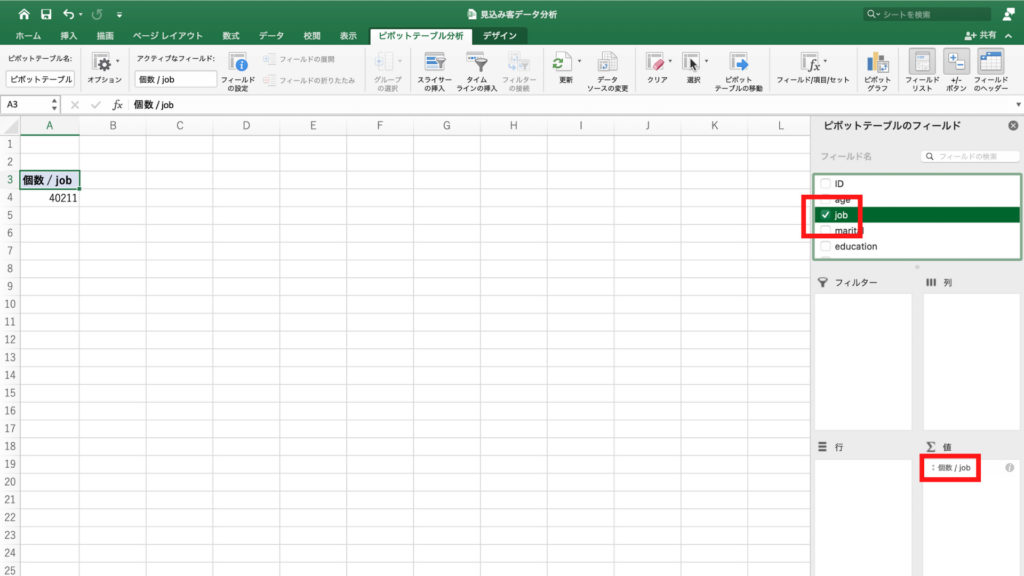
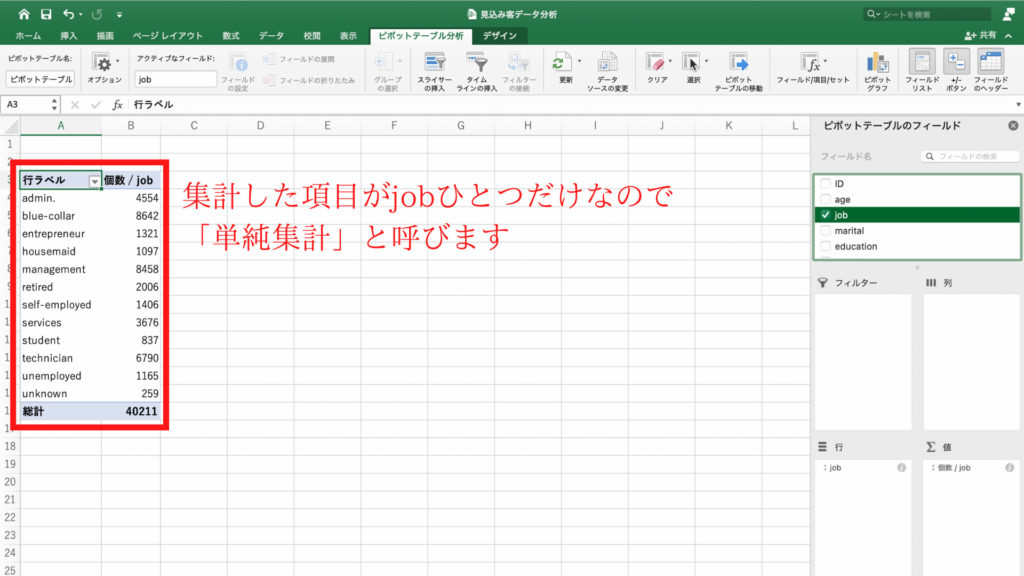
今回は職業の内訳を見たいのでピボットテーブルのフィールドから「job」を選びます。
このときに「job」にチェックボックスがありますが、ここにチェックを入れると右下の「値」のフィールドにjobの値が入ります。
そして画面左側のピボットテーブルにjobの個数が表示されました。
まだたった一つのデータですが、立派なピボットテーブルです。
jobには40211個のデータがあることがわかります。
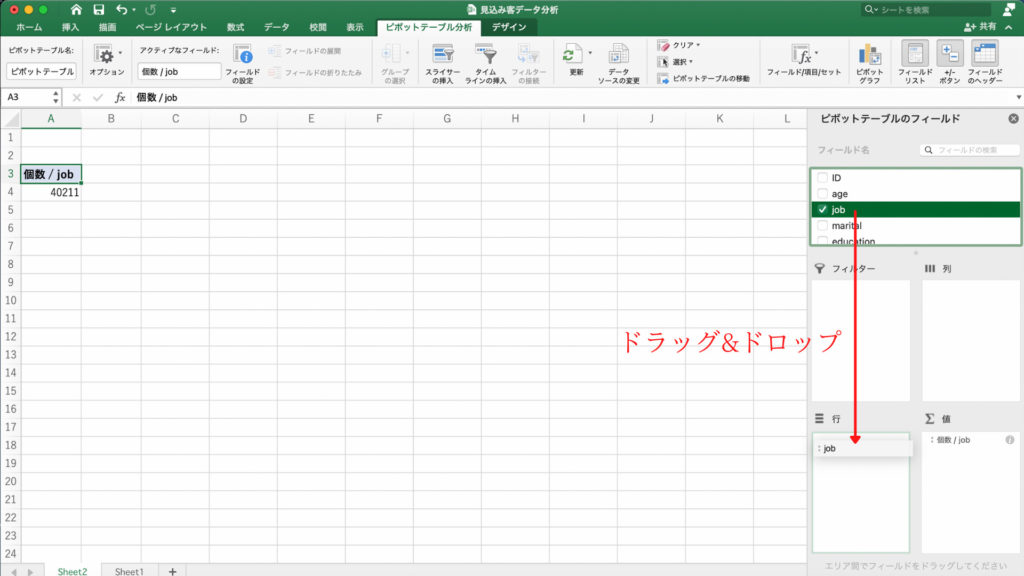
次に「job」をドラッグ&ドロップして左下の「行」のフィールドに入れます。
画面左側のピボットテーブルにjobの内訳ができました。
総計もしっかり40211です。
今回は集計した項目が職業の1つだけなので、この集計を「単純集計」と呼びます。
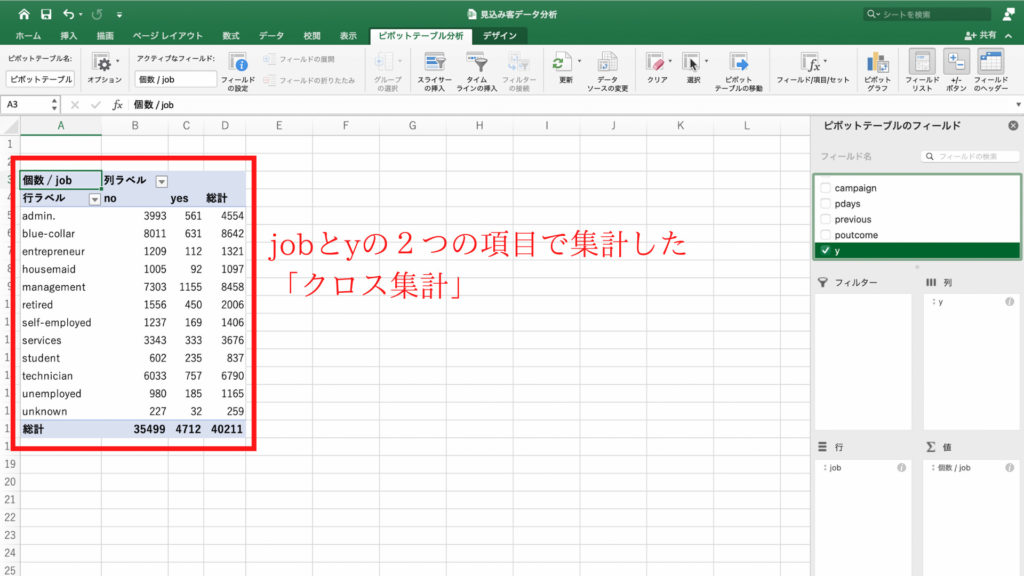
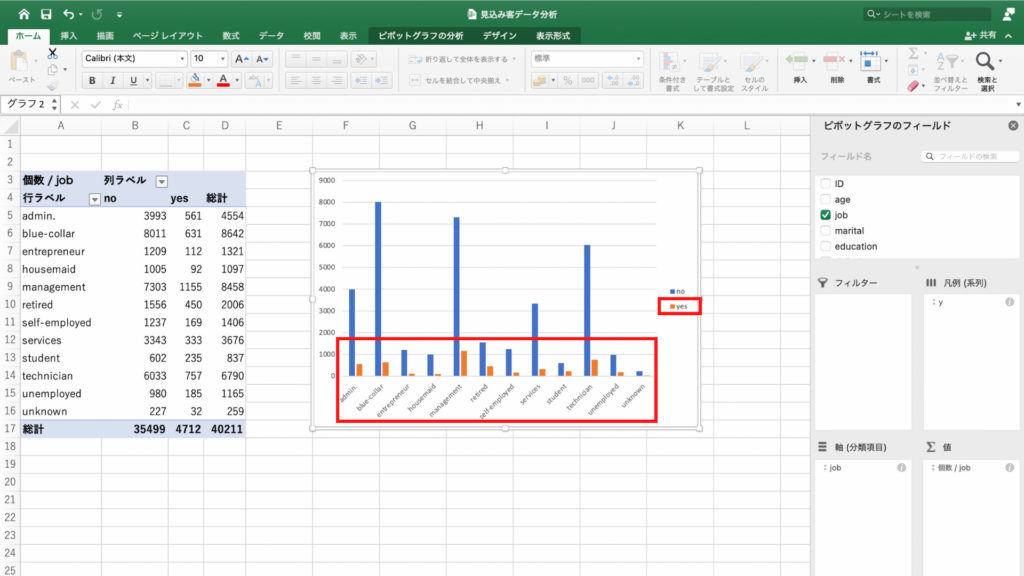
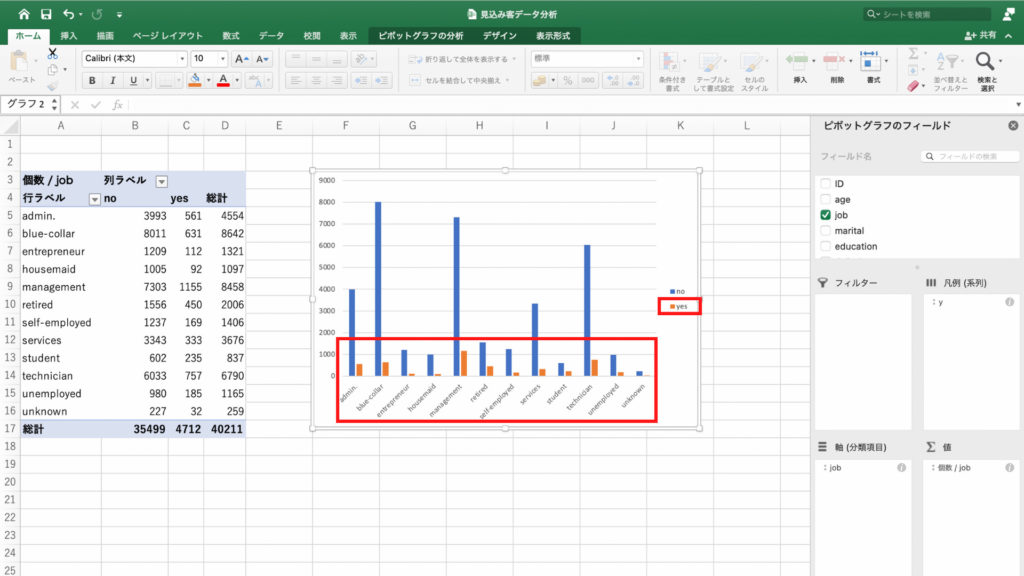
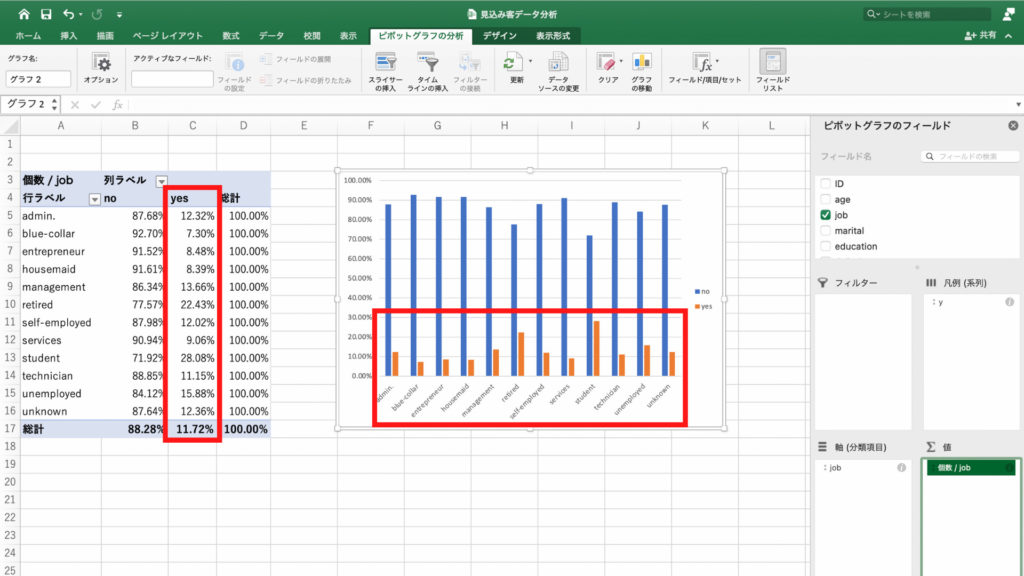
それでは、どの職業の人が新規契約を結んでくれるのか、をみてみましょう。
今回は集計した結果を「職業」と「契約の有無」の2つの項目で比較します。先ほどの単純集計に対し「クロス集計」と呼びます。
では実際にやってみます。
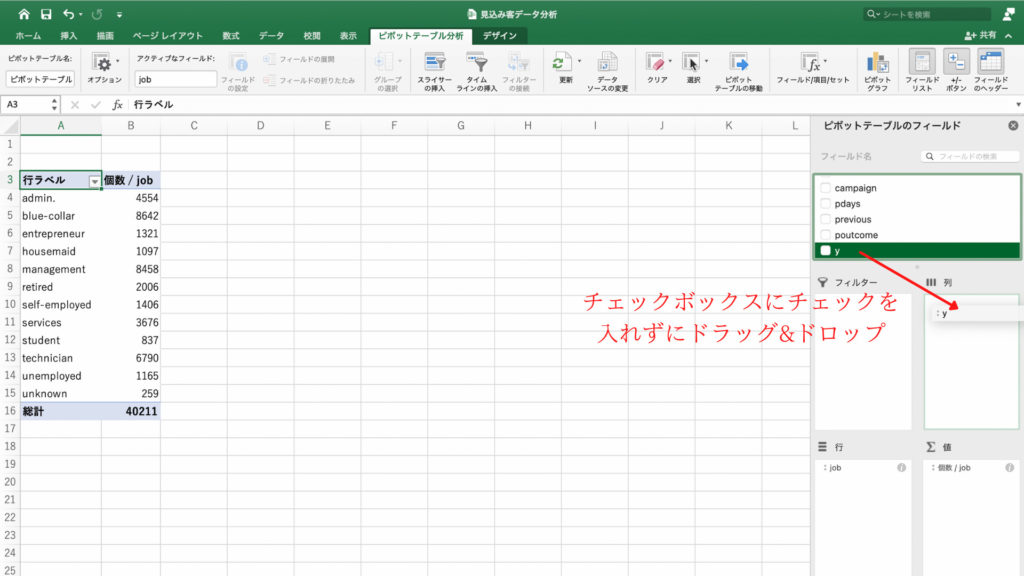
フィールドから契約の有無を表す「y」を選択します。
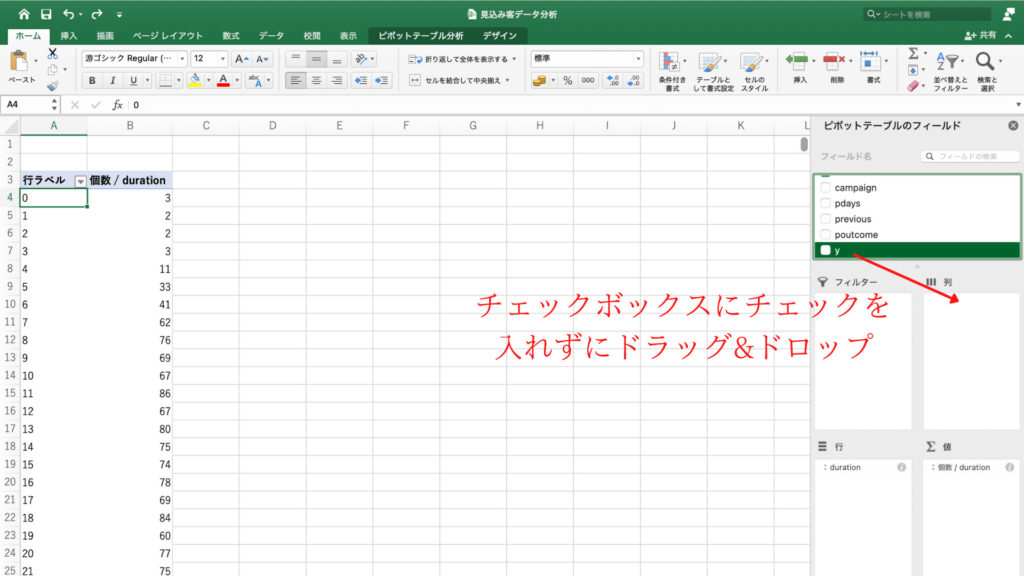
このときの注意点は「y」のチェックボックスにチェックを入れないことです。
もし「y」のチェックボックスにチェックを入れてしまうと、完成するピボットテーブルが少し見づらくなります。
そのため今回はチェックを入れずに「y」を列フィールドにドラッグ&ドロップします。
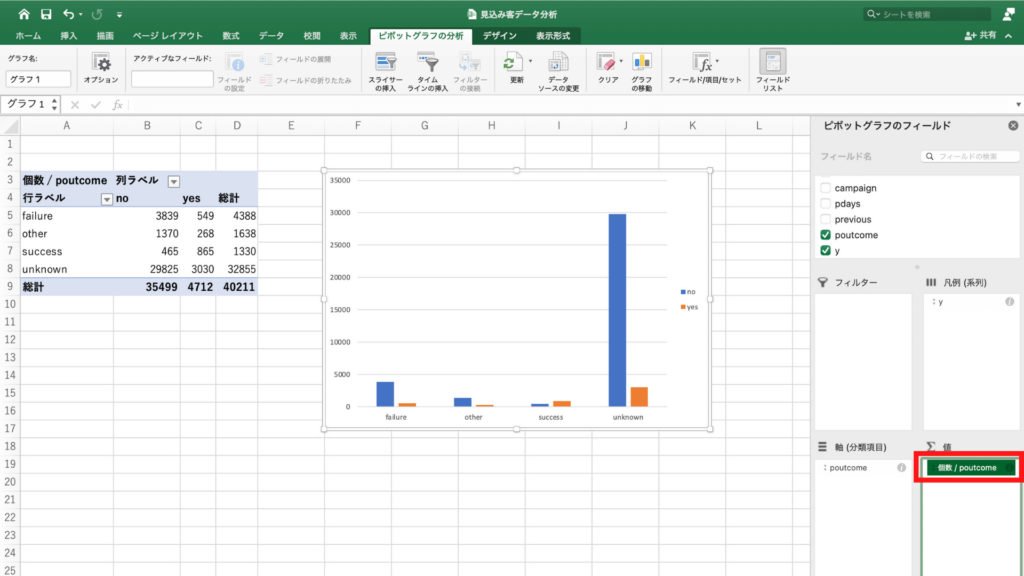
するとピボットテーブルに各職業ごとに契約無しを表す「no」と契約ありを表す「yes」の個数が表示されました。
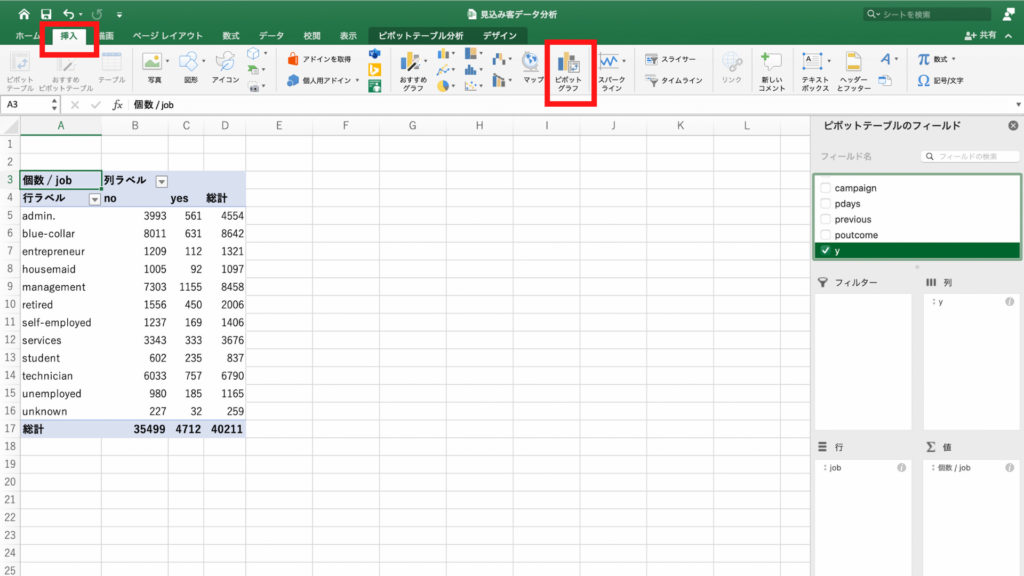
それではピボットテーブルからグラフを作って確認してみます。
「挿入」タブから「ピボットグラフ」を選んでクリック。
グラフが表示されました。
このグラフから、management層の契約数が多いことがわかります。
しかしmanagement層は総数が8458と、母数が大きいことも特徴です。
母数が大きいから契約数が多いだけかもしれません。
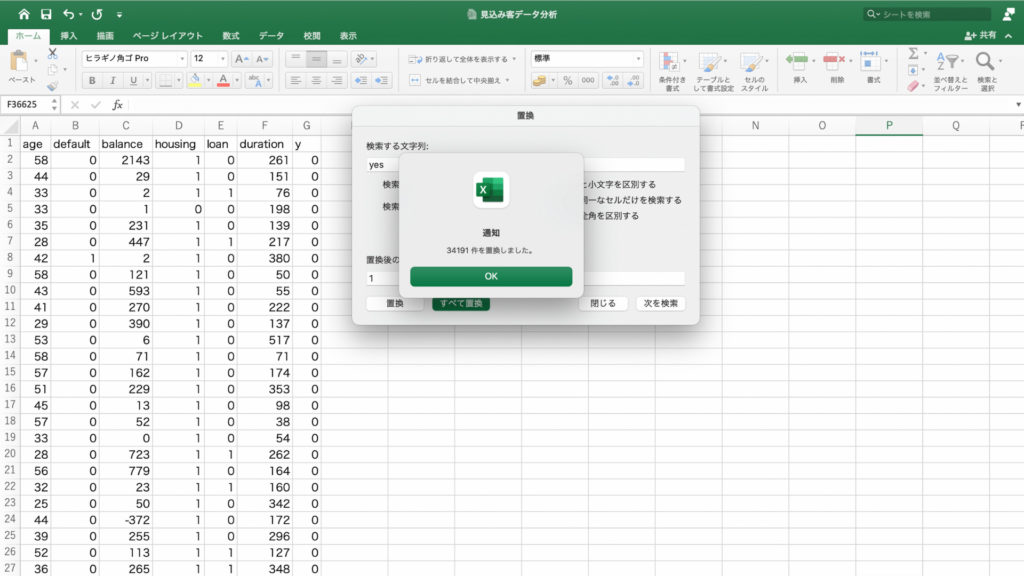
そこで今度は契約「率」で見てみましょう。
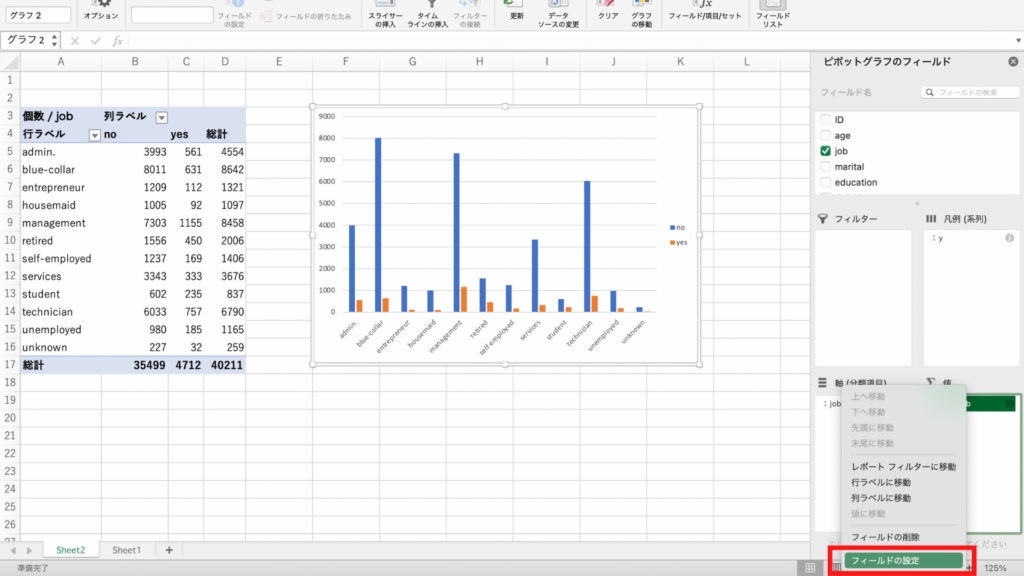
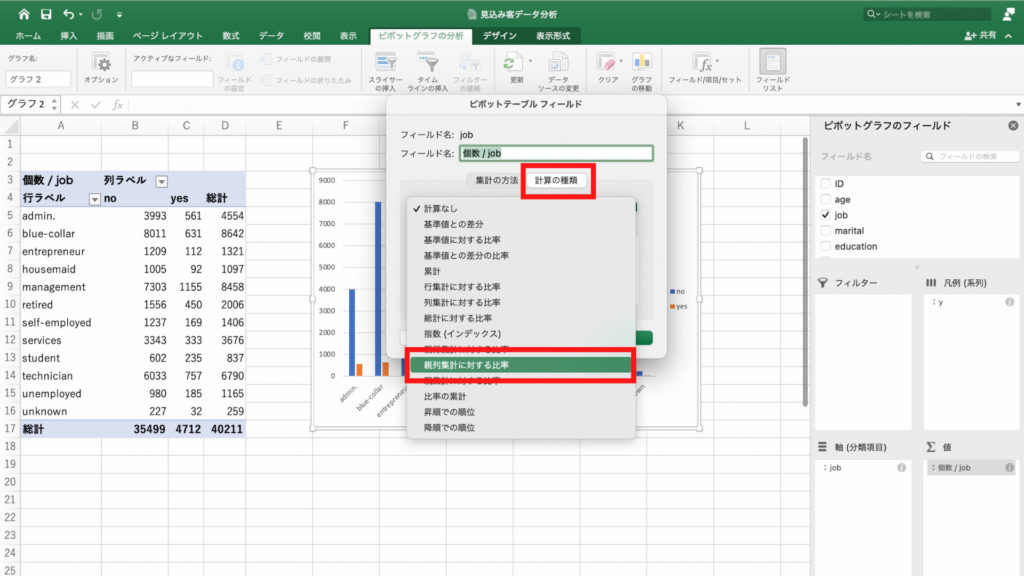
値フィールドの「個数/job」を右クリックします。
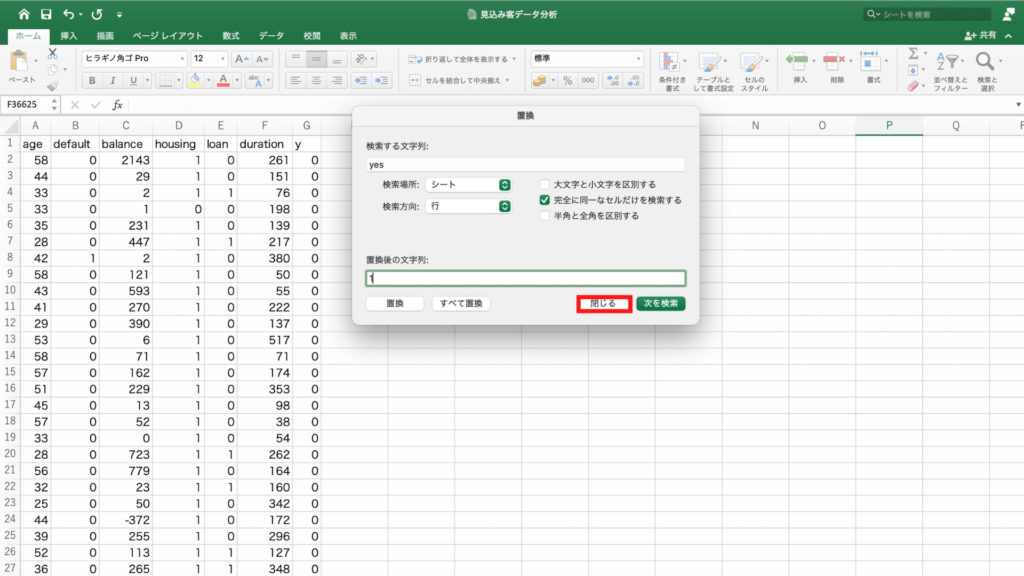
次に「フィールドの設定」をクリック。
ピボットテーブルフィールドの設定が開きますので「計算の種類」を選択。
選択肢の中から「親列集計に対する比率」をクリック。
ピボットテーブルもグラフも契約比率に変わりました。
これをよく見てみるとstudent層が一番高く、契約率が28.08%もあります。
実に3人〜4人に1人が契約している計算です。
次に高いのはretired層で22.43%で4人〜5人に1人が契約しています。
先程、一番契約数が多かったmanagement層の契約率は13.66%で7人〜8人に1人が契約している計算です。
このデータから読み取れる優先度として、まずstudent層、次にretired層だということがわかります。
4. 仮説を立てて分析する
ここまで、職業によって契約率が変わることがわかりました。
結果としてstudent層、retired層の順でアプローチするのが良いことがわかりました。
他にもいろいろな仮説を立てて検証してみましょう。
4つの仮説を立ててみました。
仮説1、前回のキャンペーンで契約した人は、今回のキャンペーンも契約するのではないか
仮説2、最終接触時間が契約に影響しているのではないか
仮説3、口座残高の多い人が契約をするのではないか
仮説4、教育水準の高い人が契約をするのではないか
順に検証してみましょう。
4-1.前回キャンペーンで申し込んだ人は今回も申し込んでくれるのではないか?
まずは仮説1、前回のキャンペーンで契約した人は今回のキャンペーンも契約するのではないか、について検証します。
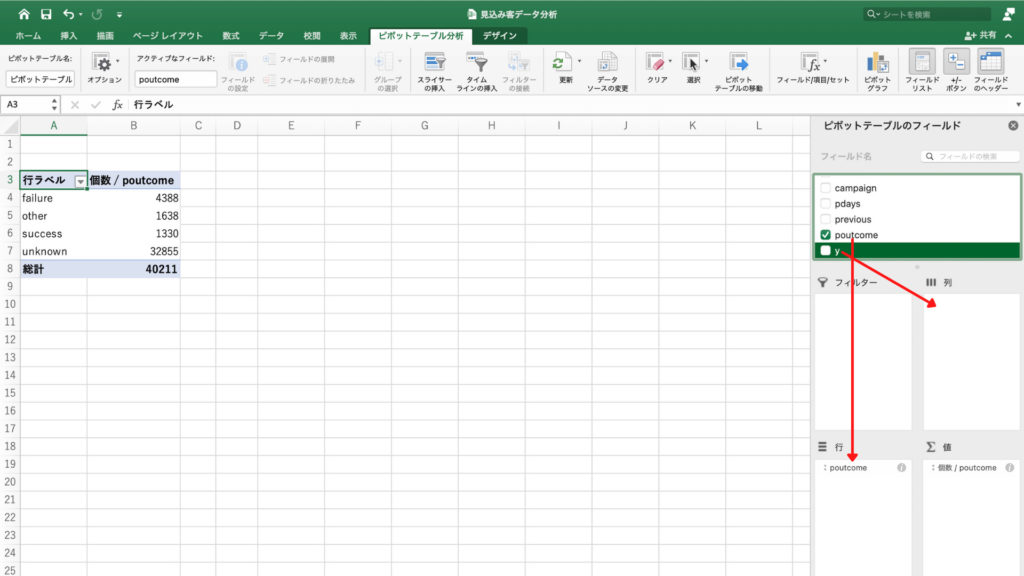
前回キャンペーンの成果である「poutcome」と、契約の有無である「y」を使用します。
職業の時と同じように「poutcome」のチェックボックスにチェックを入れ、「poutcome」を行のフィールドにドラッグ&ドロップ。
「y」のチェックボックスにはチェックを入れずに、列のフィールドにドラッグ&ドロップします。
それぞれのフィールドに無事に「poutcome」と「y」が収まりピボットテーブルにクロス集計表ができました。
この段階では「unknown」が一番個数が多く、次いで「success」の順になっています。
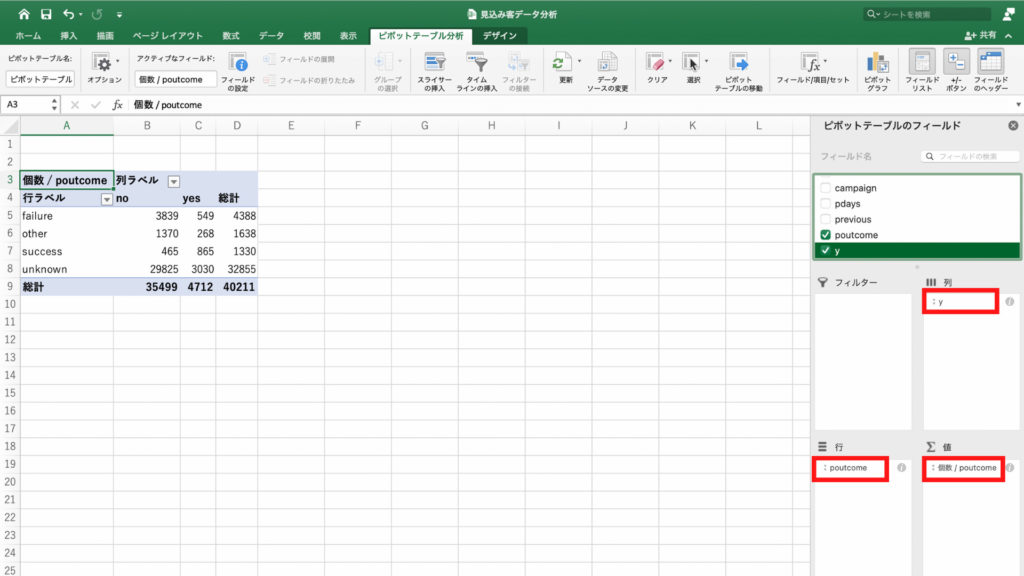
右下の「値」のフィールドの「個数/poutcome」を右クリック。
次に「フィールドの設定」をクリック。
「計算の種類」を選択し、「親列集計に対する比率」をクリック。
契約率のグラフになりました。
success、つまり前回のキャンペーンで契約した人が、今回も契約した比率は、65%だということがわかります。
3人に2人が契約したことになります。仮説の通り、前回キャンペーンで契約をした人は、今回も契約する可能性が高そうです。
4-2.申し込みは接触時間に関係しているのではないか?
2つ目の仮説、接触時間が契約に関係しているのか?について検証してみましょう。
接触時間の「duration」、契約有無の「y」を使用します。
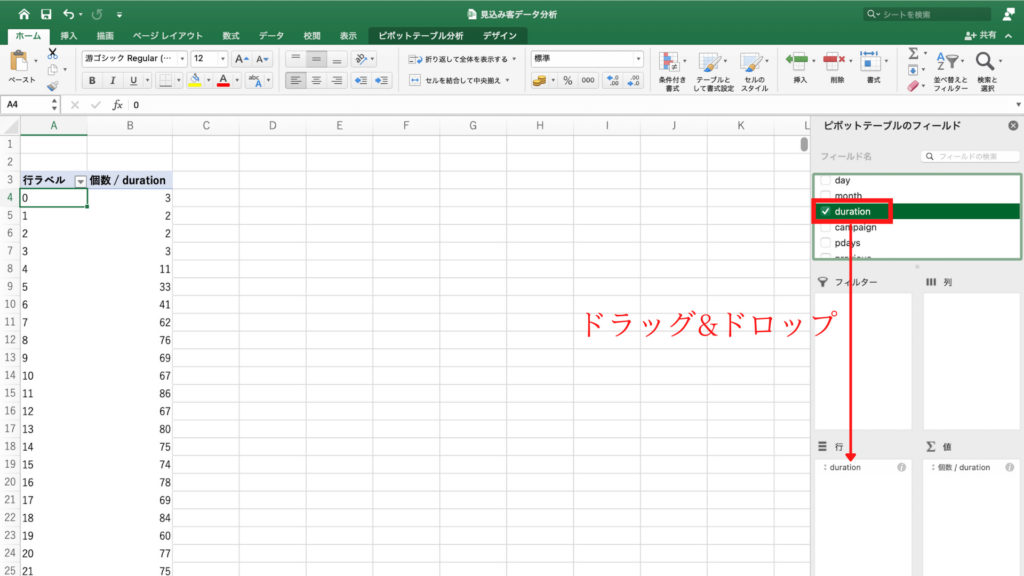
「duration」のチェックボックスにチェックをつけ、行のフィールドにドラッグ&ドロップします。
そして契約の有無を表す「y」にはチェックを入れず、列のフィールドにドラッグ&ドロップ。
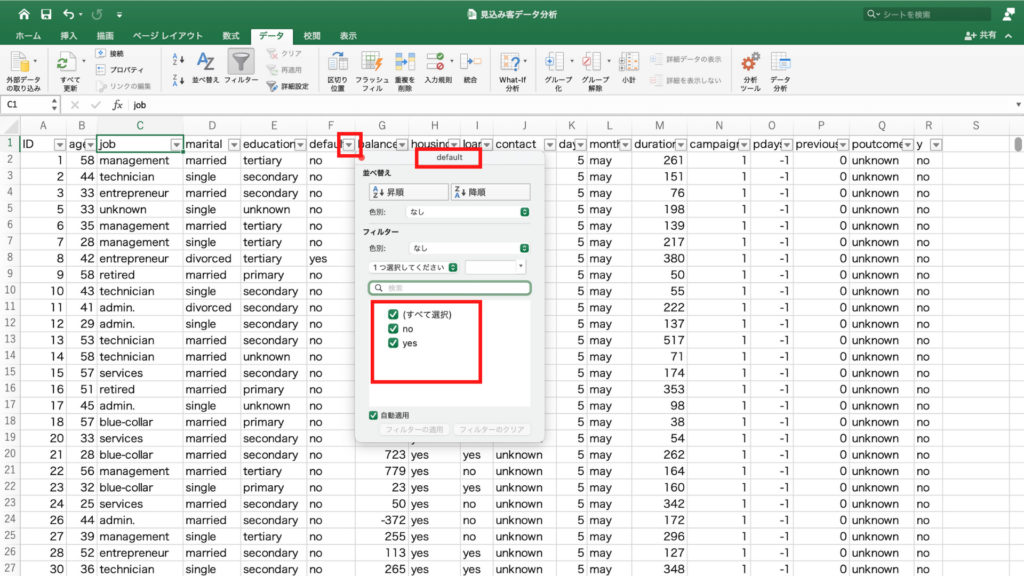
最終接触時間と契約の有無のクロス集計ができました。
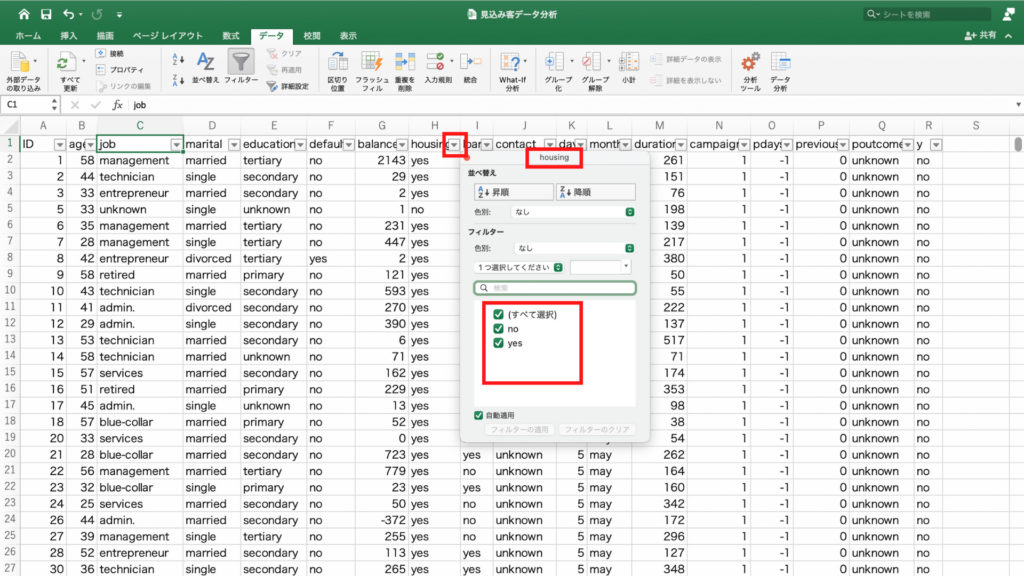
次に最終接触時間が「合計」になっているので「個数」に変更します。
右下の値フィールドの「合計/duration」を右クリック。
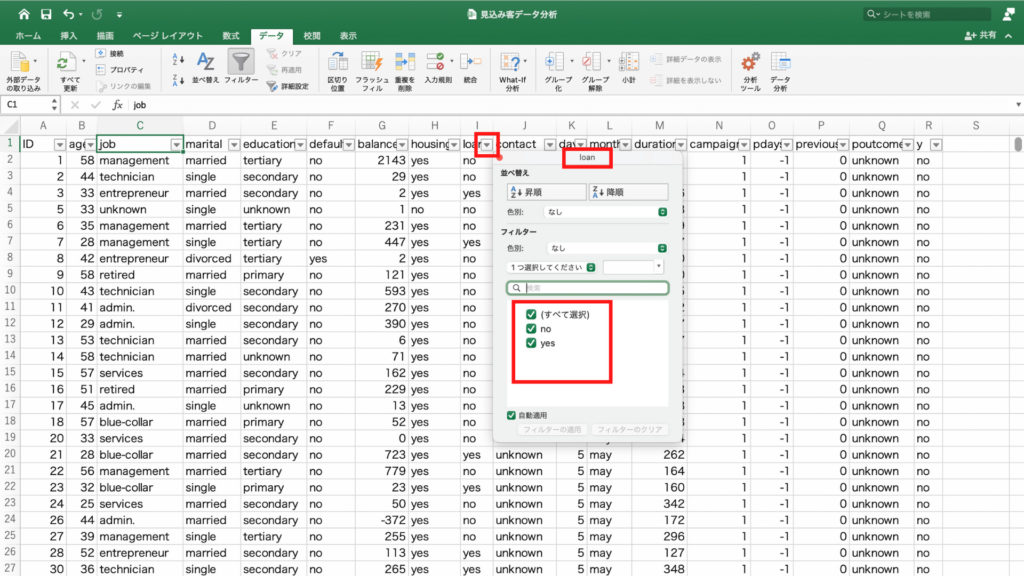
「フィールドの設定」をクリック。
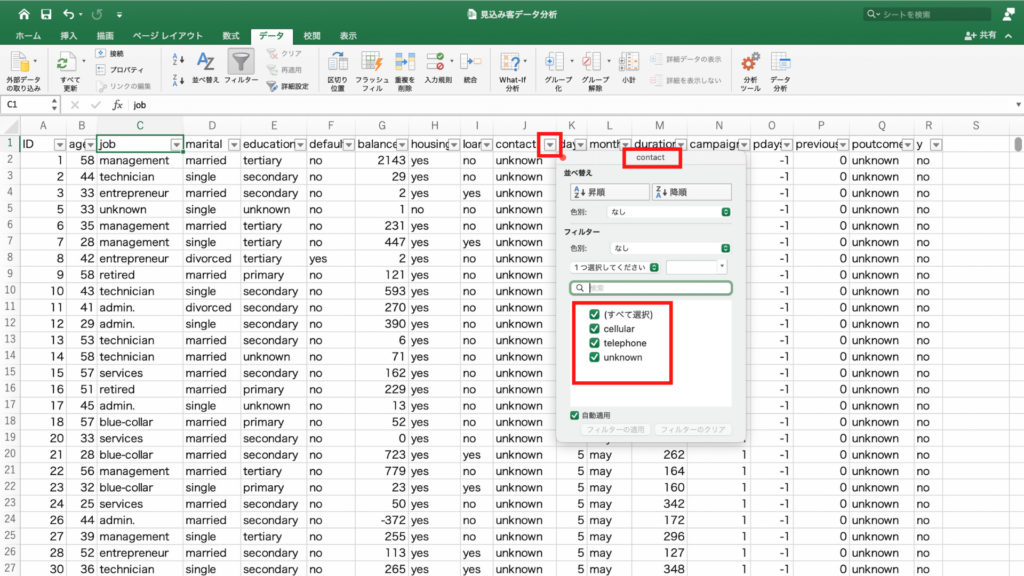
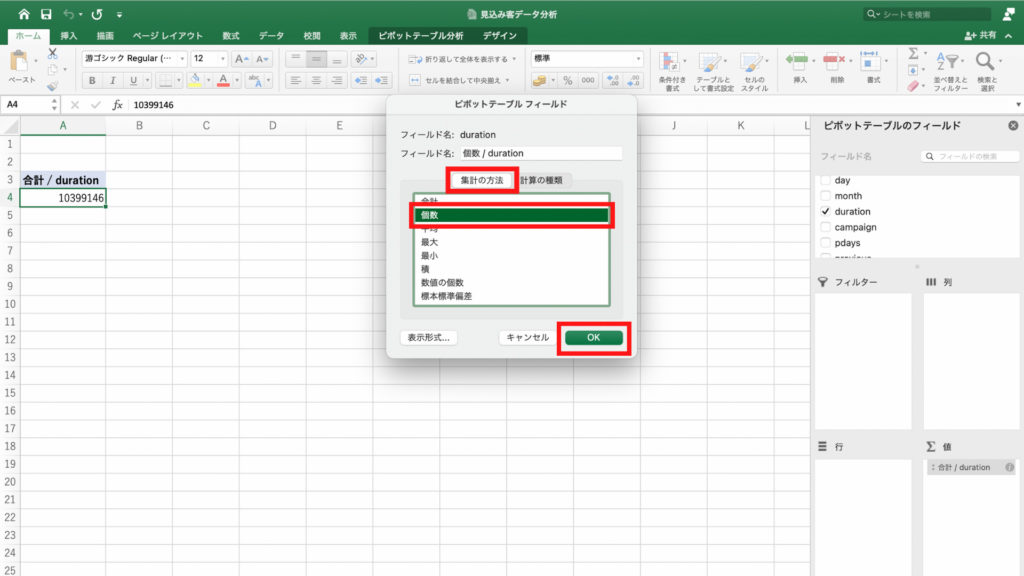
今度は「集計の方法」を選択し、「個数」を選んで「OK」。
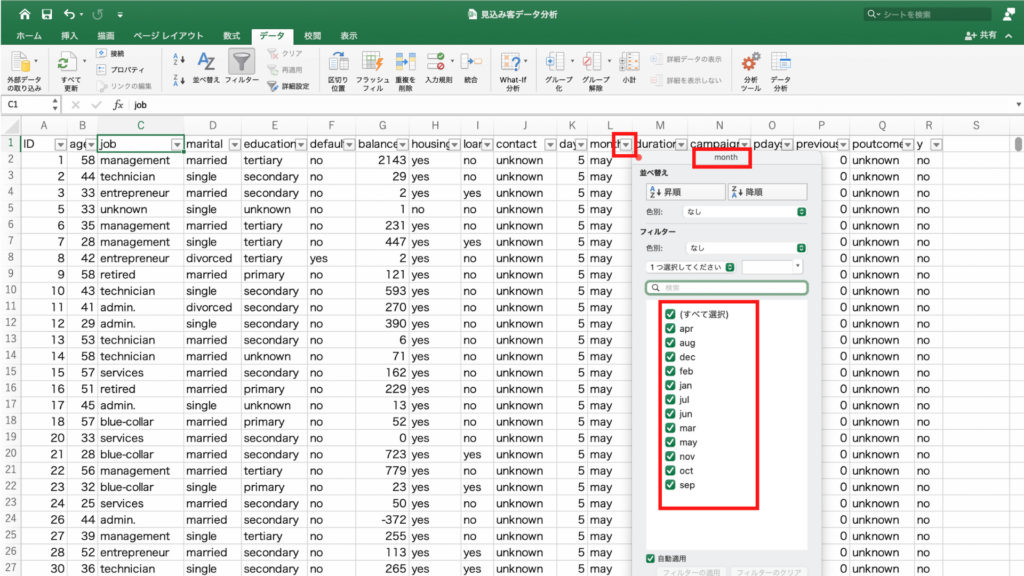
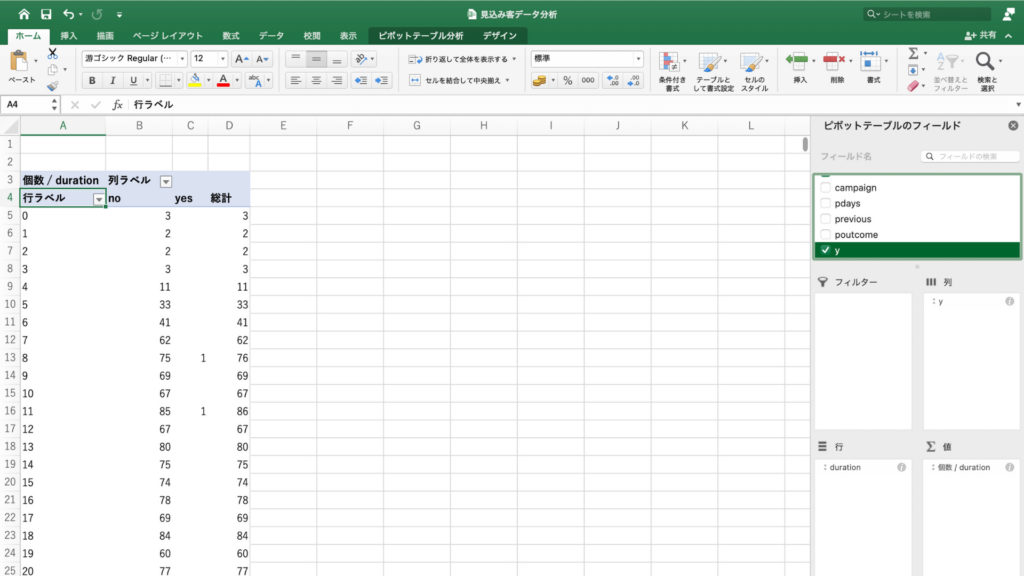
右下の値フィールドの中身が「個数/duration」に変わっているのを確認したら、画面左のピボットテーブルの行ラベルの任意のセルをクリック。
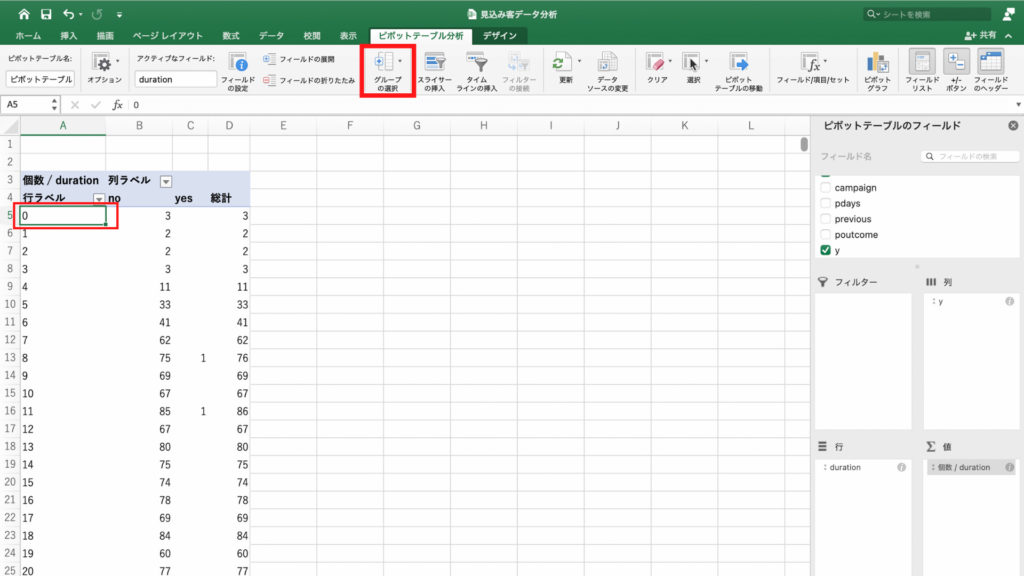
次に「ピボットテーブル分析」タブの「グループの選択」をクリックします。
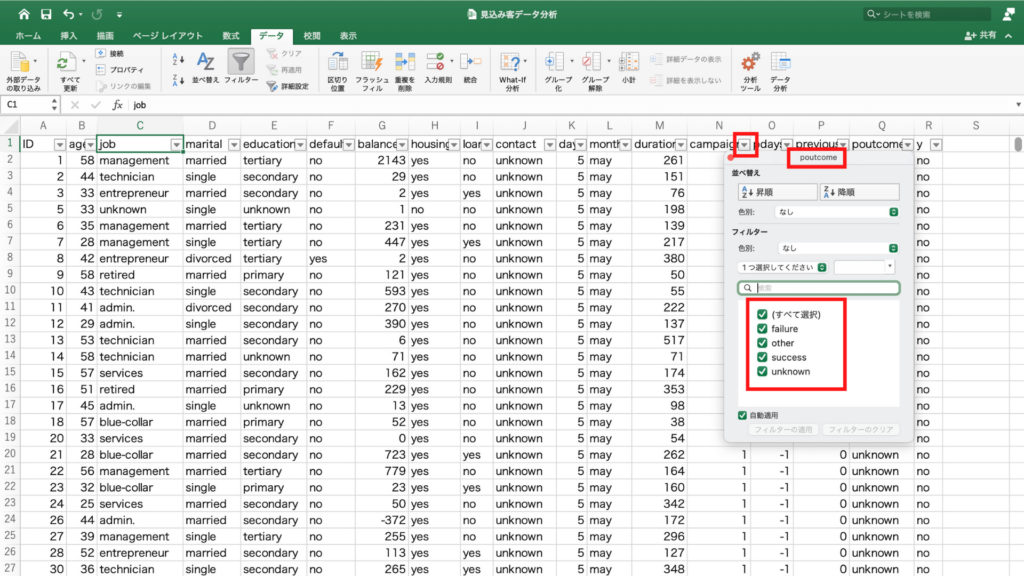
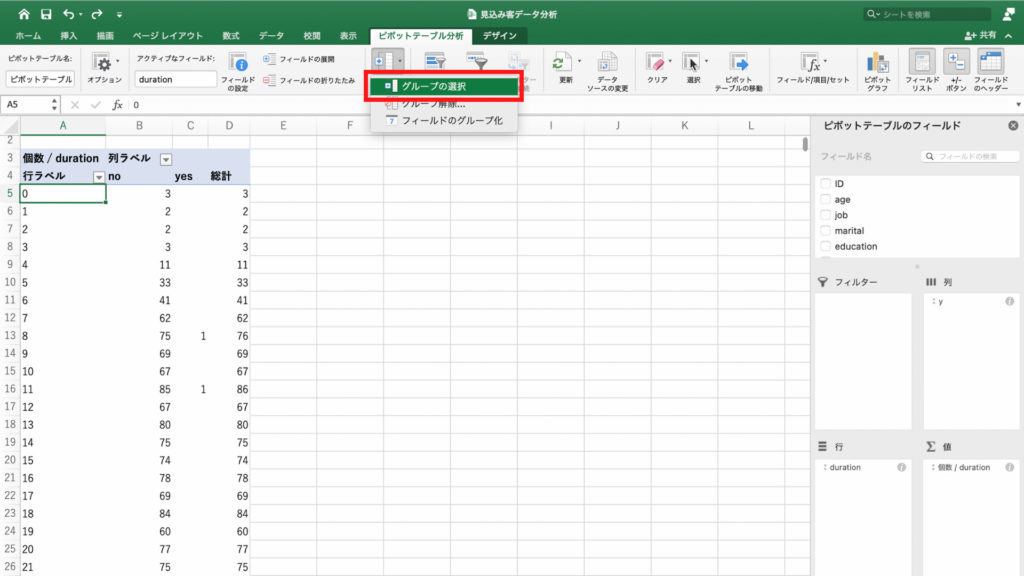
するとプルダウンが出てくるので「グループの選択」をクリック。
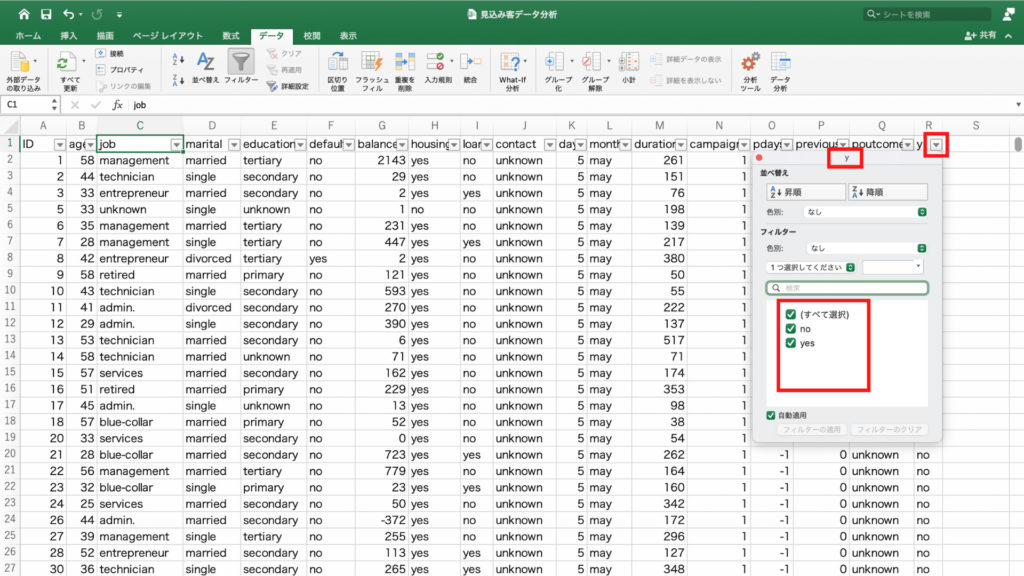
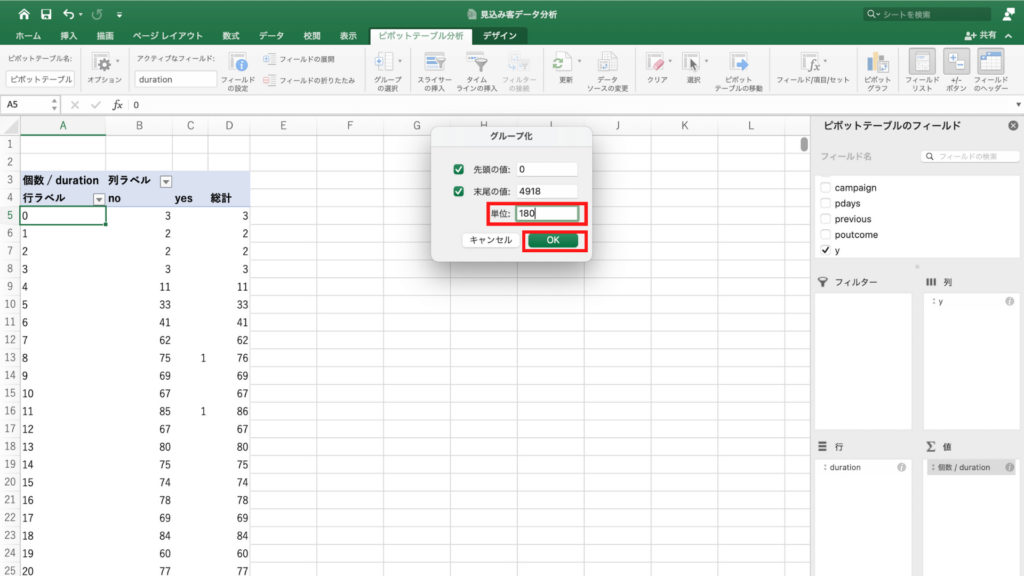
「グループ化」の中の単位をここでは3分単位にしたいので「180」に変更して「OK」。
するとピボットテーブルが3分単位にまとまり、だいぶスッキリとしました。
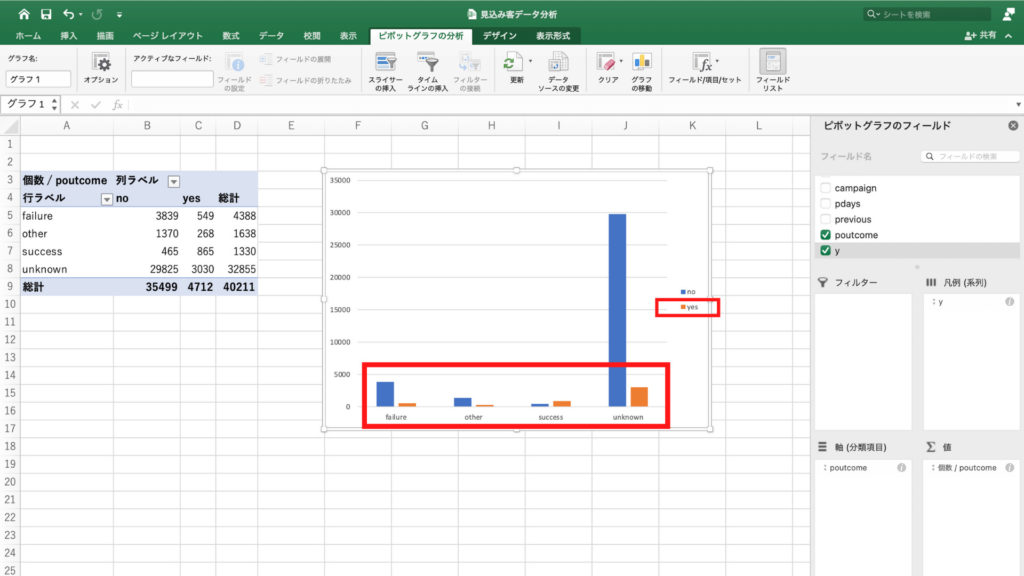
今度は「ピボットテーブル分析」タブの中の「ピボットグラフ」のアイコンをクリックしてグラフを作成します。
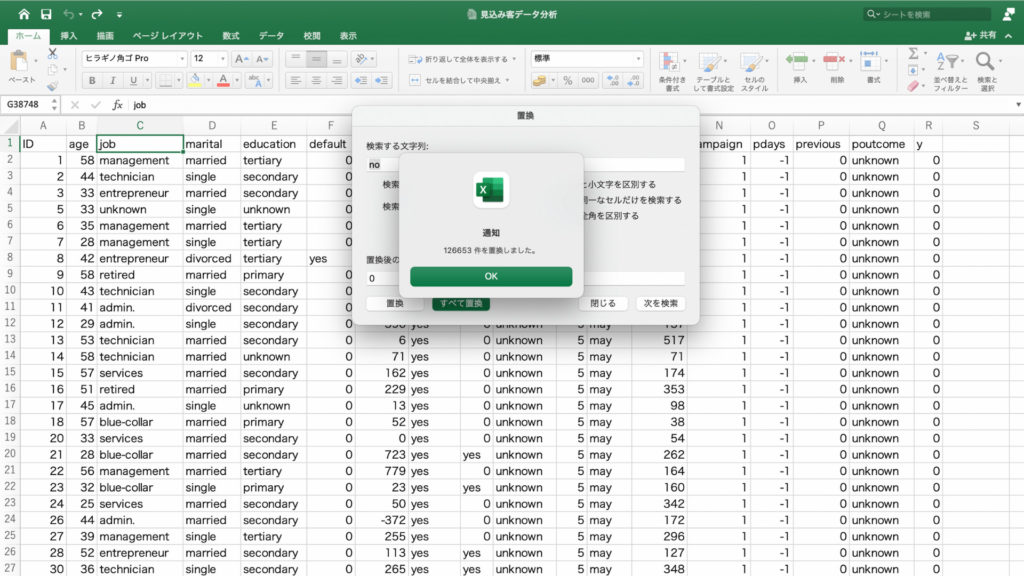
最終接触時間と契約の有無を示すグラフが表示されました。
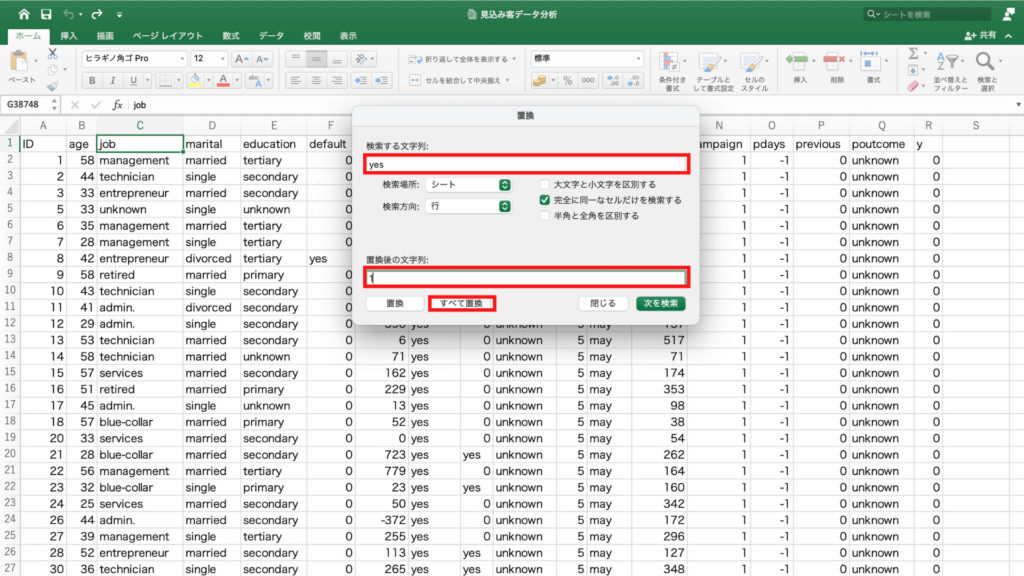
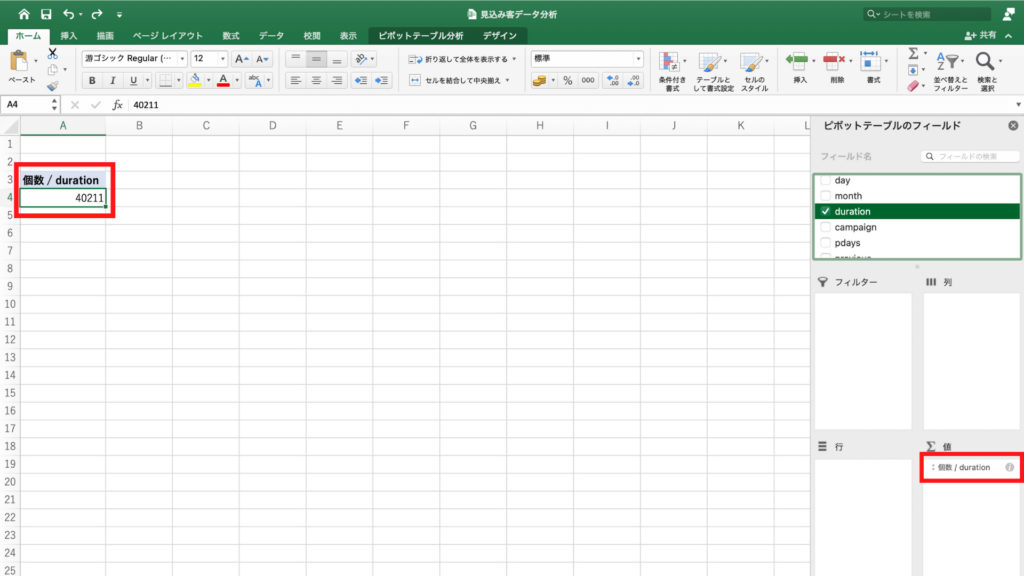
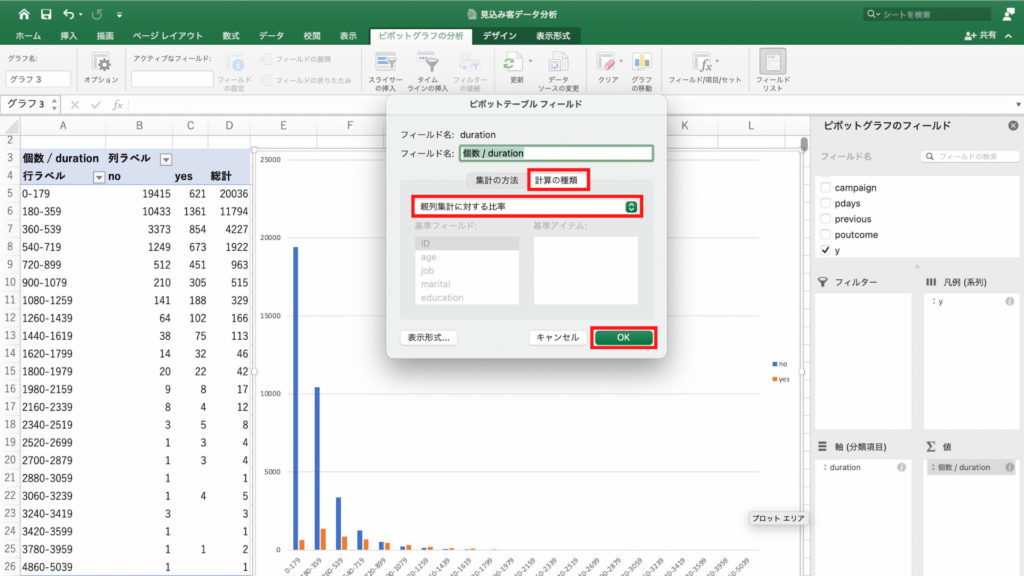
今回も今までと同じく契約率を確認したいので、値フィールドの「個数/duration」を右クリック。
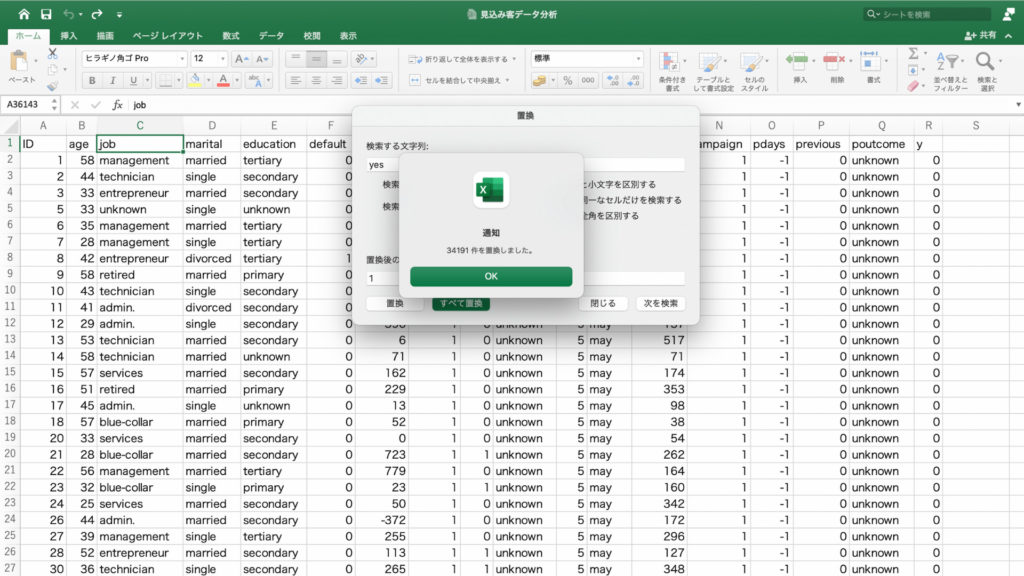
「フィールドの設定」をクリック。
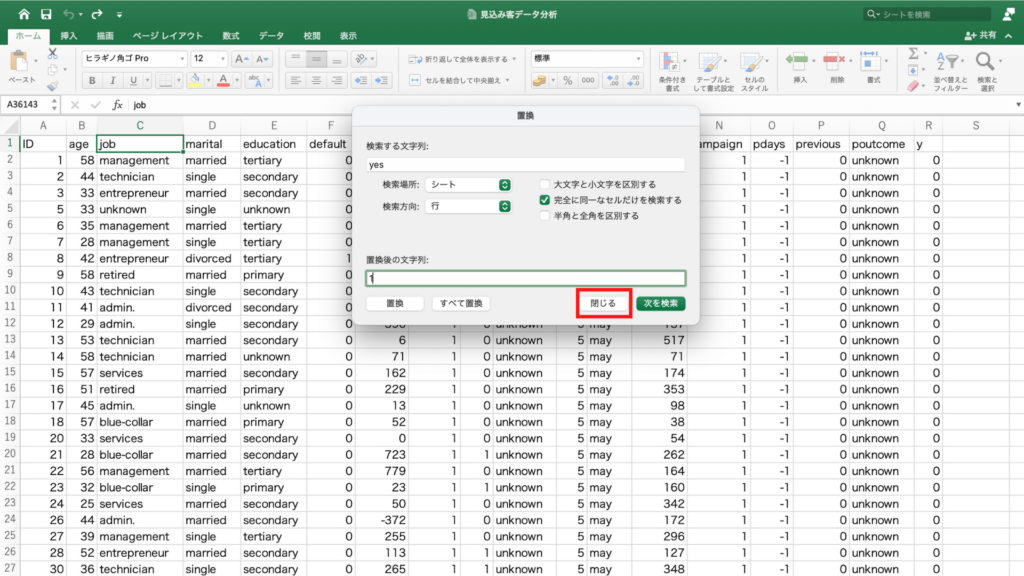
「計算の種類」を選んで、「親列集計に対する比率」を選択し「OK」。
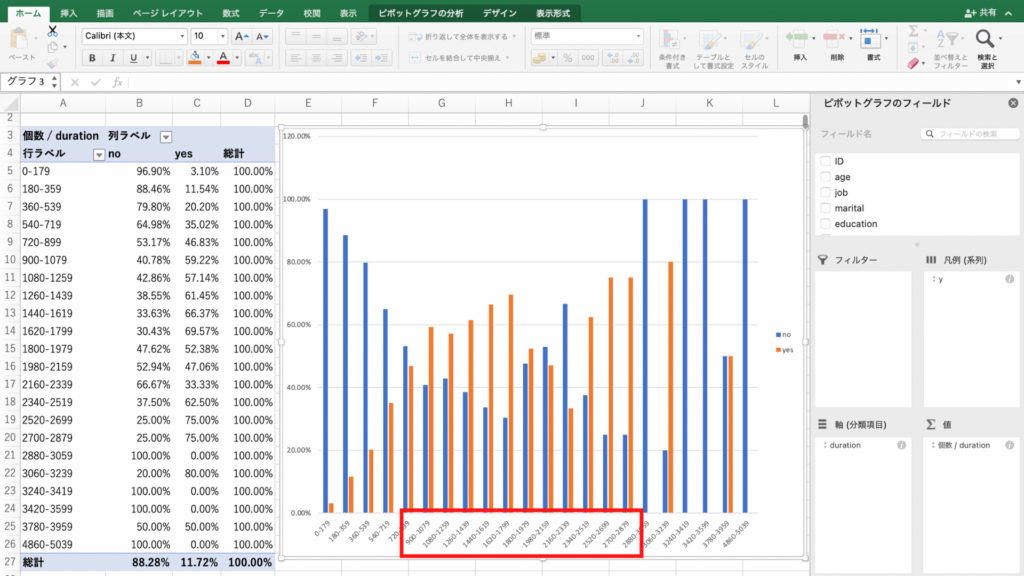
すると最終接触時間と契約率を表すグラフができました。
このグラフから、あまり接触時間が短すぎても、長すぎても契約に結びつきにくいことが確認できます。
営業マンが顧客と商談するときは900秒から2880秒。
分に換算すると15分から48分の間くらいがちょうど良いようです。
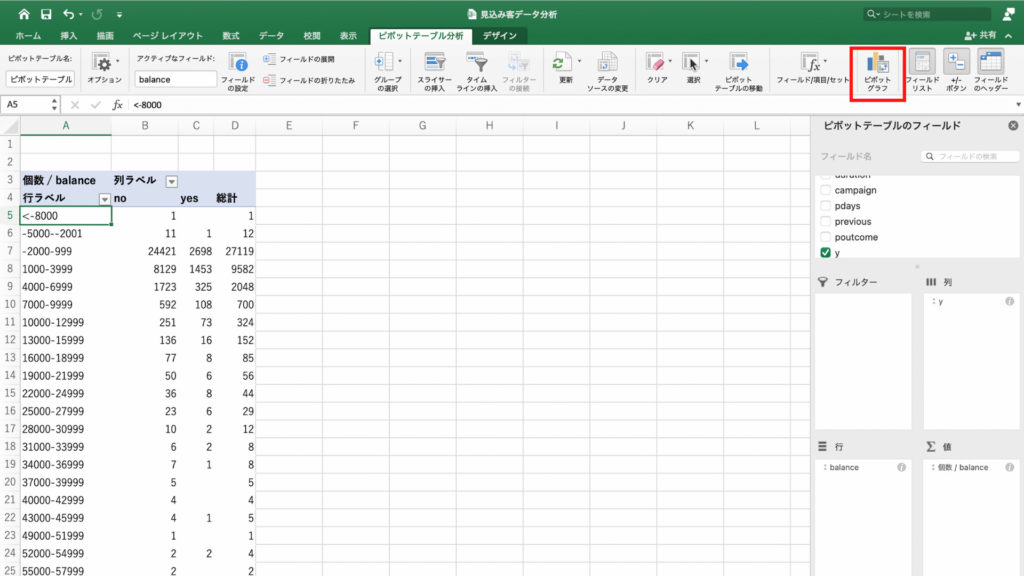
4-3.口座残高が多い人が契約をしてくれるのではないか?
今度は仮説の3つ目、口座残高の高い人が契約をするのかについてみてみましょう。
この仮説に対する分析の方法は、最終接触時間と契約率の分析方法と同じです。
値フィールドと行フィールドに「balance」, 列フィールドに「y」を入れます。
現在、値フィールドの値が「合計/balance」となっているので「個数/balance」に変更。
「ピボットテーブル分析」タブの「フィールドの設定」をクリックします。
「集計の方法」を選択し、「個数」を選んで「OK」。
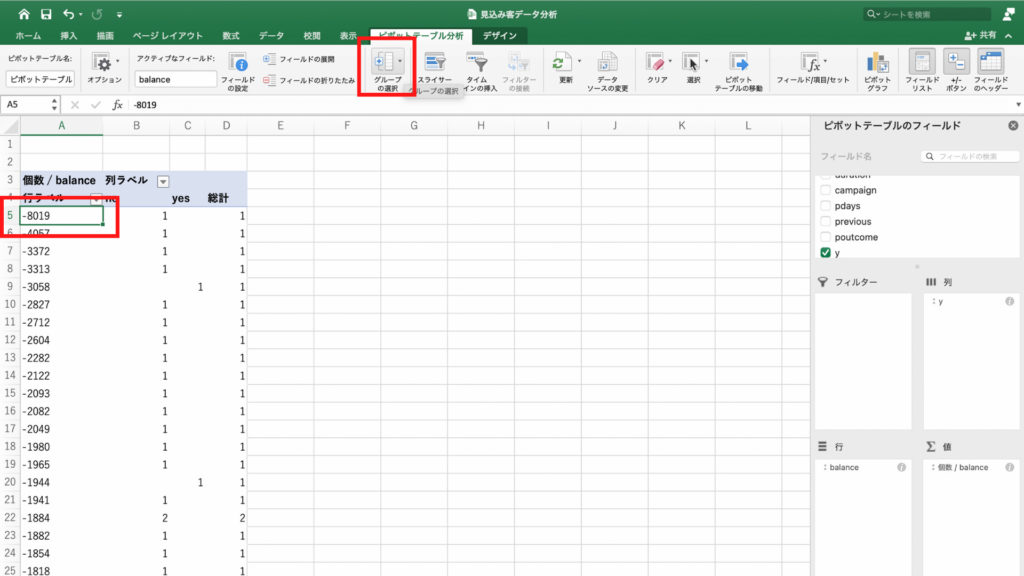
データが多いのでグループ化し、見やすくします。
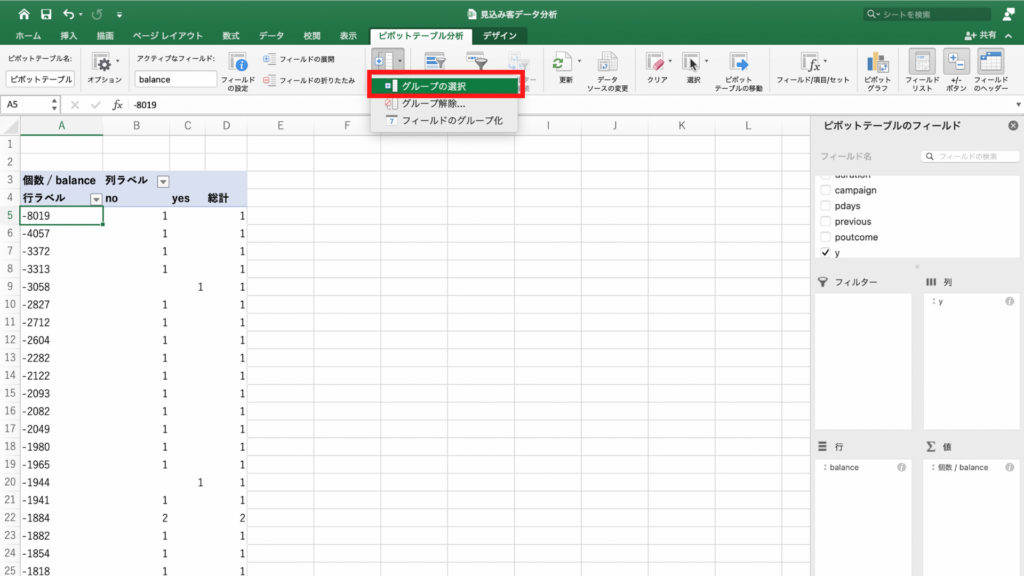
ピボットテーブルの行ラベルのセルをどれか選んで、「グループの選択」アイコンをクリック。
「グループの選択」をクリック。
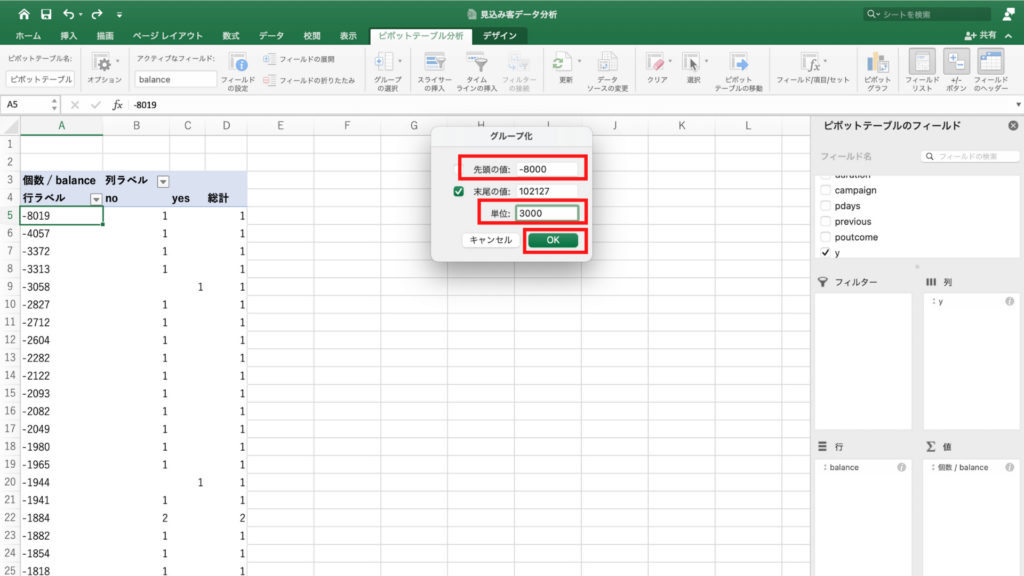
先頭の値が-8019となっていますが、綺麗な数字にしたいので-8000と入力します。
次に単位は3000ユーロ単位にしますので3000と入力。
最後に「OK」を押します。
ピボットテーブルが少し綺麗になりました。
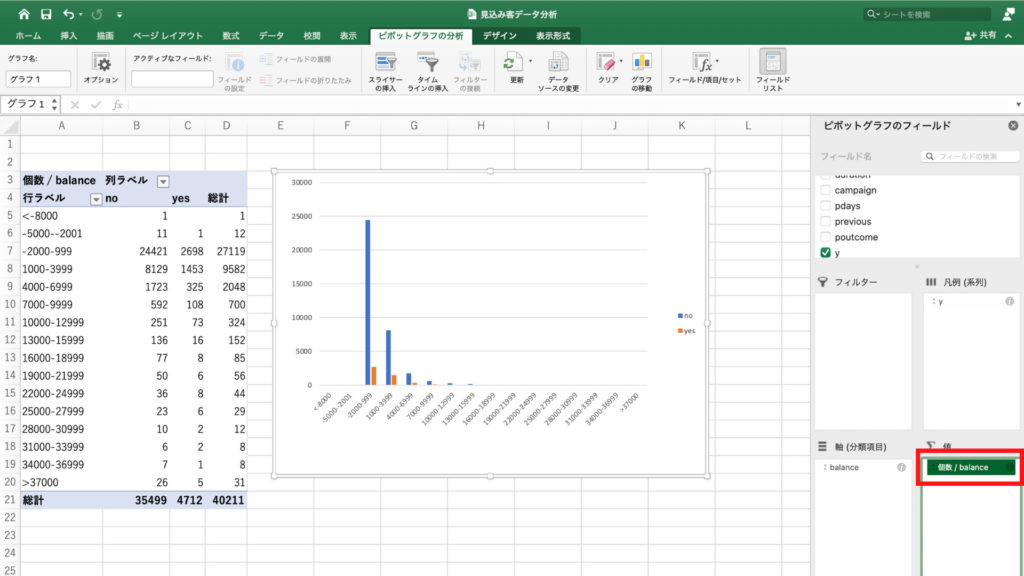
次にグラフを作りたいので、画面上部の「ピボットグラフ」アイコンをクリック。
グラフが表示されました。
このグラフとピボットテーブルを見ると、37000以上の人がほとんどいません。
そのため37000以上の人たちをまとめてしまいます。
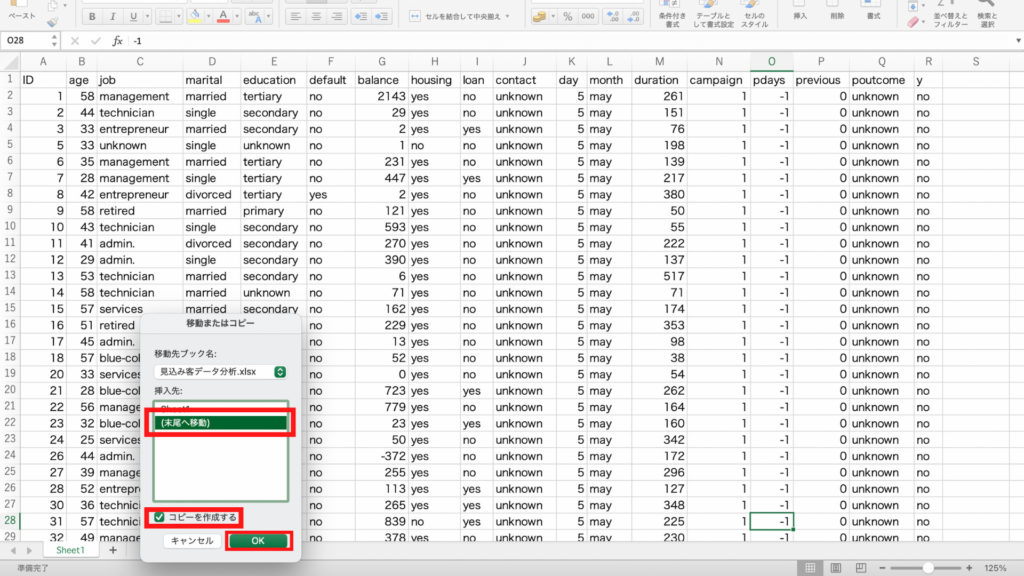
もう一度「グルーブ選択」アイコンをクリックし、「末尾の値」に36999を入力します。
OKを押したら、37000以上の人のデータがまとめられていることがわかります。
次に、契約率を確認したいので、値フィールドの「個数/balance」を右クリック。
そのまま「フィールドの設定」をクリック。
「計算の種類」をクリックし、「親列集計に対する比率」を選択。
最後にOKを押します。
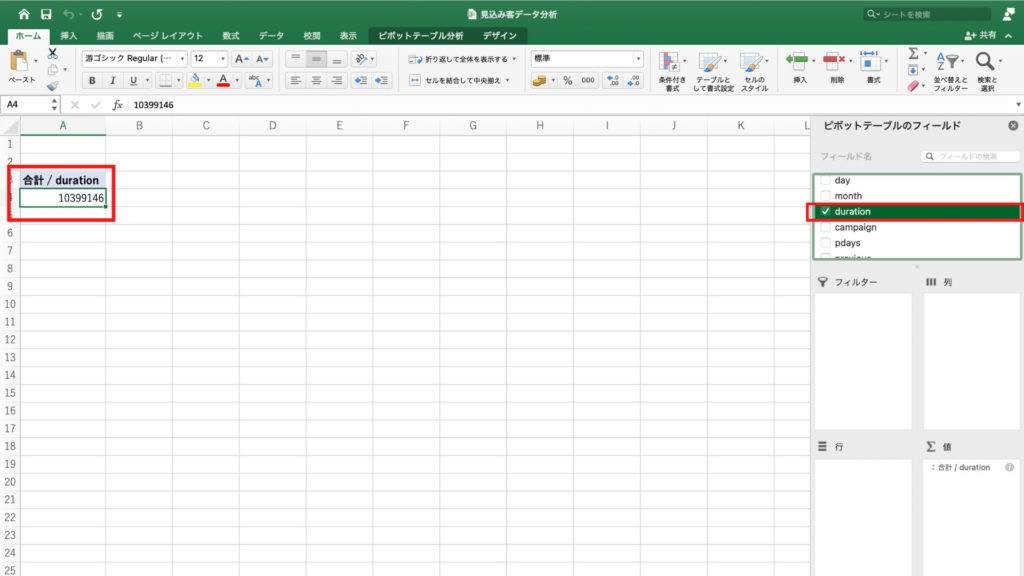
すると口座残高別の契約率が表示されました。
しかし、口座残高が増えても契約率が増えることはなさそうです。
ほとんど横ばいで、驚くことに口座残高がマイナスの人も定期預金の契約をしていることがわかります。
よって、この仮説は成り立たないと判断できます。
4-4.教育水準が高いほど、契約をしてくれるのではないか?
最後に4つめの仮説、教育水準が高いほど定期預金を契約するのではないか?について検証します。
今まで同じように値フィールドと行フィールドに「education」、列フィールドに「y」を入れます。
ピボットテーブルに教育水準と契約の有無のクロス集計ができました。
次にグラフを表示します。
画面上部の「ピボットグラフ」アイコンをクリック。
グラフが表示されました。
次は契約率を確認します。
「個数/education」を右クリックし、続いて「フィールドの設定」をクリック。
「計算の種類」を選択し「親列集計に対する比率」を選び「OK」。
すると契約率を表したグラフができました。
このグラフとピボットテーブルの数値をみると、tertiary, unknown, secondary, primaryの順に契約率が高いようです。
5.優先順位を反映したアプローチリストを作る
これまでの仮説検証を通してわかったことをまとめてみましょう。
1:職業はstudent層、retired層の順で契約率が高い
2:前回キャンペーンで契約してくれた人は今回も契約率が高い
3:最終接触時間は15分から48分程度が最適
4:教育水準の契約率が高いのは「tertiary, unkown, secondary, primaryの順」である
以上のことから、どういった人に優先的にアプローチをすれば契約につながるかが見えてきましたね。
では、そもそも今回配布されたデータ全体の契約率がいくらだったのかを確認しましょう。
まず、ピボットフィールドの値フィールドと行フィールドにyを入れます。
すると総計に対するyesの個数が表示されました。
次に値フィールドの「個数/y」を右クリック。
「フィールドの設定」をクリック。
「計算の種類」を選択し、今度は「列集計に対する比率」を選びます。
「計算の種類」が「列集計に対する比率」に変更されていることが確認できたら「OK」をクリック。
するとyesの値が11.72%であることが確認できます。
それでは実際に優先順位を反映させると、この11.72%の契約率がどのように変化するかを見ていきましょう。
まず値フィールドに y を入れます。
行フィールドには poutcome と job をドラッグ&ドロップします。
今回は優先順位通り poutcome、job の順番で入れました。
そして列フィールドに y をドラッグ&ドロップ。
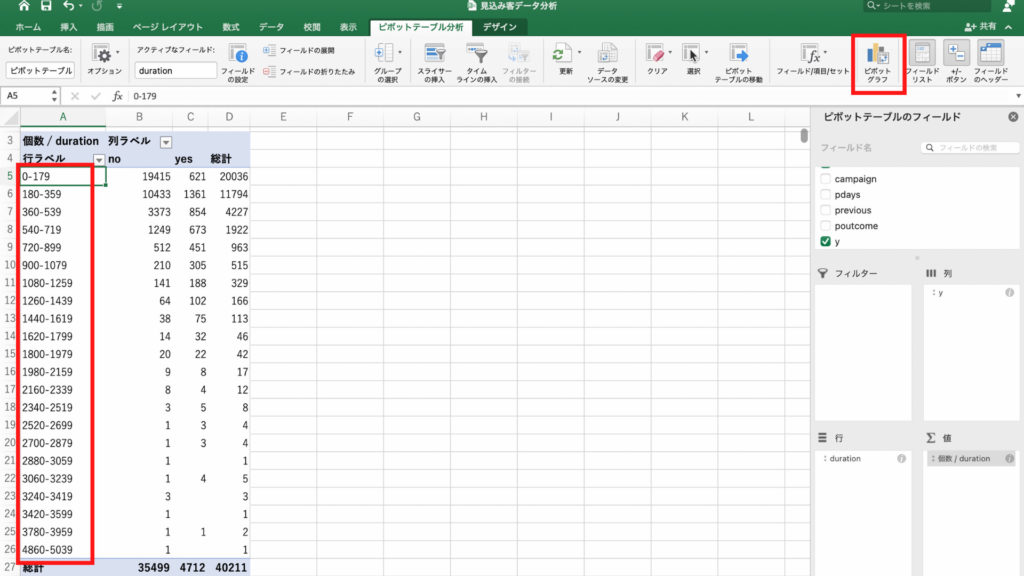
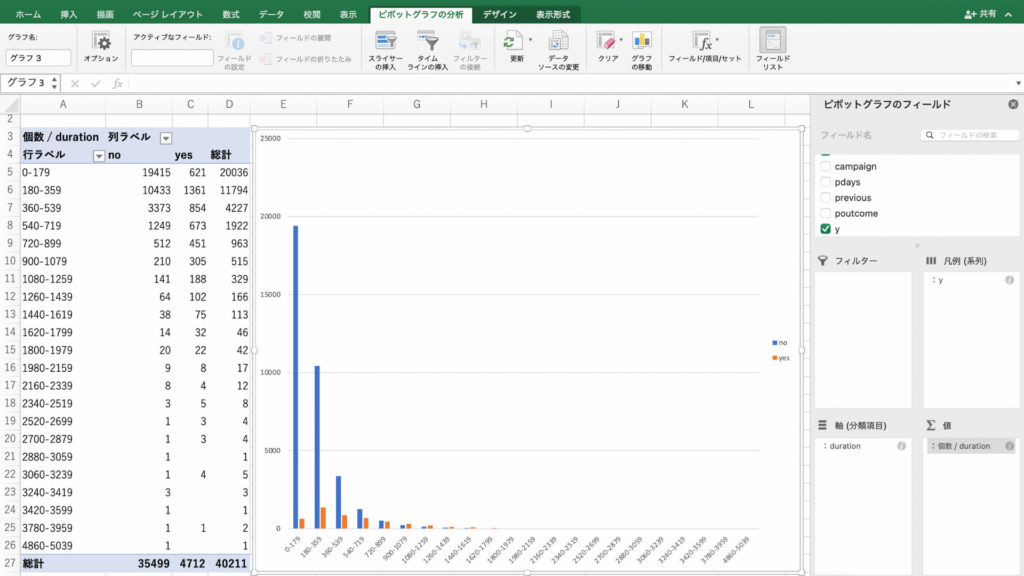
次に「行ラベル」の文字の右側にあるアイコンをクリックします。
これはフィルターのアイコンです。
フィルターとは条件を選択してデータを取り出せる便利な機能です。
「フィールドの選択」で「poutcome」を選び、「success」だけを選択します。
このときにもしデフォルトで全ての項目にチェックがついている場合は、ひとつひとつ外しても良いのですが、(すべて選択)で一度すべてのチェックを外してから目的の項目だけチェックすると楽に選択できます。
次に「フィールドの選択」で「job」を選び、「student」だけを選択します。
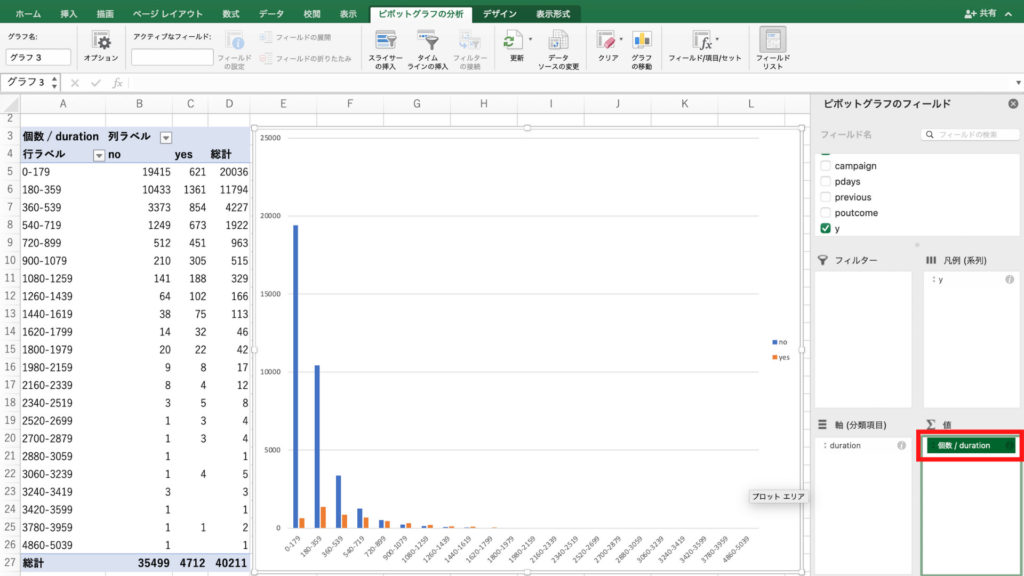
すると前回のキャンペーンで契約してくれた人の中から、student層だけを抜き出すことができました。
なんと77人中、56人が契約しています。
続けて契約率を表示してみましょう。
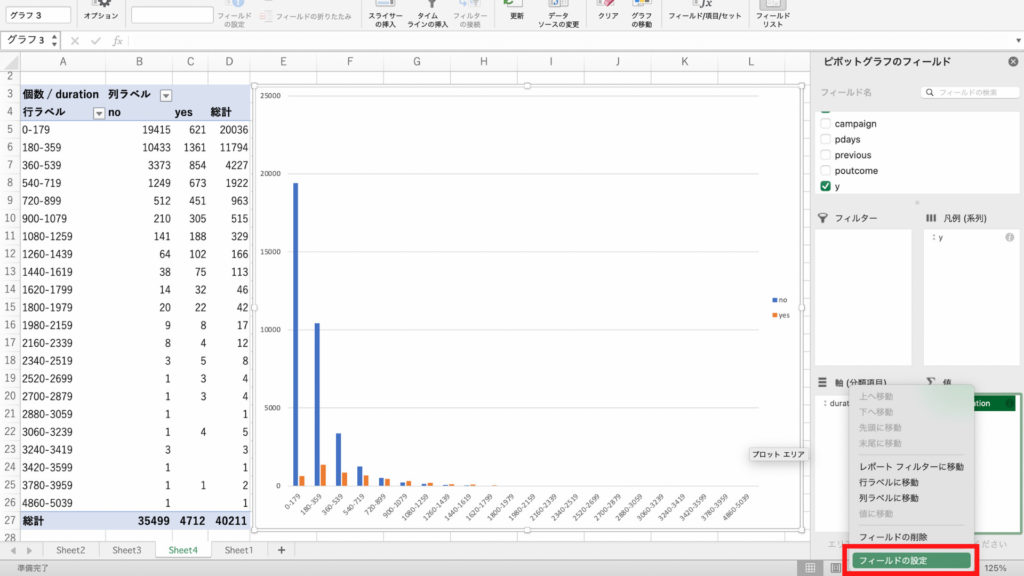
値フィールドの「個数/y」を右クリック。
「フィールドの設定」をクリック。
「計算の種類」を選択し、「総計に対する比率」をクリック。
「計算の種類」が「総計に対する比率」になっていることが確認できたら「OK」。
すると契約率が72.73%になっていることが確認できます。
もともと11.72%の契約率でしたから、かなり契約率が高くなることがわかります。
さて、今回のテーマは、「新規で定期預金を契約してくれそうな顧客を探す」ことです。
あなたは営業マンから、顧客リスト「test_data.csv」を渡されました。
ここで使用する顧客リストの「test_data.csv」に含まれている年齢や職業などの項目は、これまで分析をしてきた「train_data.csv」と同じです。
唯一違う点は、「test_data.csv」には、契約の有無を表す「y」がないことです。
契約前なので、この情報はありません。
それではここから、優先的にアプローチ をする顧客リストを作ってみましょう。
これまでの分析から、優先する条件を反映させてみます。
最優先項目は、前回キャンペーンで契約してくれた人、
その次に、職業をstudent層に絞ってみましょう。
まず、概要欄にあるリンクから「test_data.csv」をダウンロード、今まで使ってきたフォルダに保存します。
Excelに読み込みます。先ほどとは少し違った方法でやってみます。
新規のエクセルファイルを開き、「データ」タブの「外部データ取り込み」アイコンをクリックします。
取り込むファイルの種類は「テキストファイル」を選択します。
先にお話ししたようにcsvファイルは、カンマで区切られた「テキストファイル」です。
忘れていた方は、ここでもう一度押さえておきましょう。
取り込むデータは「test_data.csv」を選択し「データ取り出し」をクリック。
「選択したデータのプレビュー」を見るとカンマで区切られていることが分かるので、「区切り記号付き」を選択し「次へ」。
区切り文字は「カンマ」を選択し「次へ」。
区切った後の列のデータ形式は、今回も「標準」を選択し「完了」をクリックします。
無事にデータがインポートできました。
データを確認すると「y」列がないことが確認できます。
ファイル名を変更しておきましょう。
「保存」アイコンをクリック。
名前を入力し、「保存」をクリック。
ファイル名が「優先度を反映したアプローチリスト」に変わりました。
test_data.csvに含まれていたデータの個数を確認してみましょう。
ID列で確認したところ5001とあります。
見出しの1行を差し引くとデータの個数は5000,つまり5000人分の顧客データがあることがわかります。
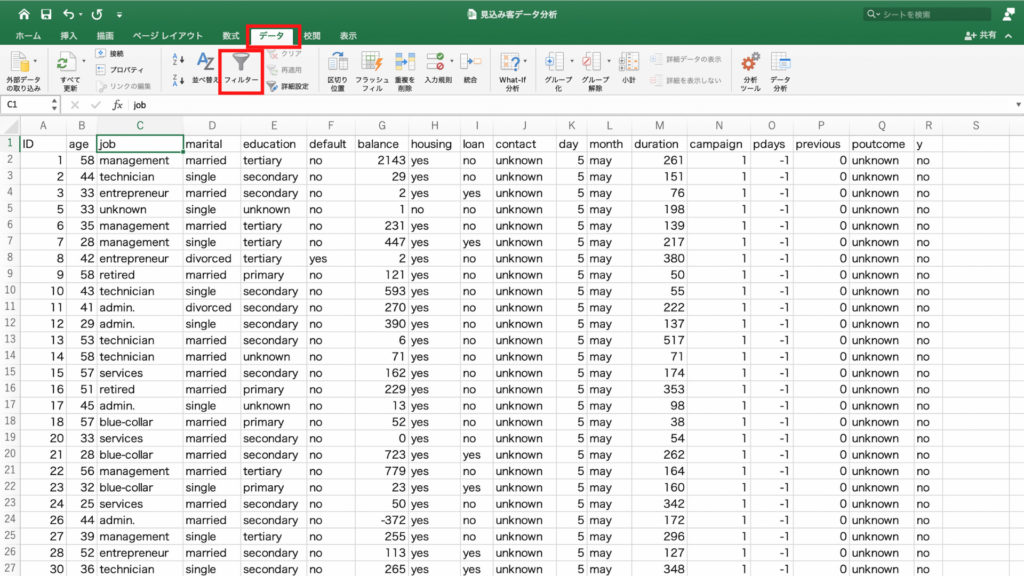
続いてフィルター機能を使ってアプローチする顧客を絞っていきます。
「データ」タブから「フィルター」アイコンをクリック。
見出しの行に下向きの三角印(▼)が入りました。
最優先の前回キャンペーン契約者を抜き出します。
右に少しスクロールして「poutcome」の三角印をクリックします。
「success」だけにチェックを入れます。
続いて「job」の三角印をクリックし「student」だけにチェック。
すると前回キャンペーンで契約してくれた学生さんのデータが全て抽出されました。
ちょうど10名のリストですが「優先度を反映したアプローチリスト」ができました。
この10名から最優先にアプローチすると良いでしょう。
このときの接触時間はなるべく15分から48分に間に収まるように営業をかけると良いかもしれません。
もし10名で少ないようでしたら、student層の次に契約率が高かったretired層を含んでもよいかもしれません。
その場合はフィルター機能で「student」に加え「retired」にもチェックを入れると簡単にリストができます。
データの個数を確認すると39で、見出しを差し引くと38人がリストアップされました。
このようにエクセルを使ってデータを分解し比較することで、効率よく顧客にアプローチするためのリストを作成することができました。
データの分解の仕方や比較の仕方で精度や戦略も変わってきますので、実務ではいろいろとチームで議論しながら進めると良いと思います。
